HA Admin Manual
1. Introduction
System administrators and users want their cluster to be available with minimal down-time. While a failing compute or GPU node slightly reduces compute power, problems with head, login, and storage nodes can make a system completely unusable.
Login nodes usually don’t provide data-critical services, so it’s easy to achieve redundancy for them by having multiple, identical ones. However, the head-node is quite different, because the central cluster services running on it depend on non-redundant data in a database or filesystem. To achieve redundancy for it, a second head-node is needed, and a mechanism must be provided to share the cluster service’s data between the two heads. As well, control software is required to detect hardware and software failures, and to automate the recovery of services on the second head-node when the first one fails. These requirements also apply to storage nodes.
The collection of software and mechanisms provided to achieve this kind of high-availability (HA) we call the Qlustar HA Stack (QHAS). With appropriate hardware providing the necessary redundancy, QHAS can provide Qlustar services that are fully protected from SPOFs (single points of failure) by setting up proven HA configurations on head and storage nodes.
For many years, QHAS was based on Corosync and Pacemaker (COPA), which has been the synonym for open-source HA software. However, it eventually became apparent that the design of COPA is not well suitable for HPC setups, especially for installations with large storage clusters using Lustre or BeeGFS. For example, little control is offered over automation levels: maintenance mode may only be switched on or off, either operating everything manually or fully trusting COPA’s decisions.
In practice, this means that even small mistakes in HA configuration, resource scripts, etc. may cause unnecessary service failovers or resets, despite no real errors occurring in the services. This is especially common in the implementation and early production phases of a new cluster, which introduces unnecessary downtime and may give the impression that an HA cluster is less stable and available than a non-HA one.
As well, COPA was designed for heterogeneous clusters having potentially many HA nodes, each running different services of nearly any kind. This great flexibility incurs more complexity. Nowadays, such use cases are usually better served by a container-based microservice environment running on Kubernetes, which has built-in redundancy.
Compared to COPA-based clusters, highly available HPC/AI cluster setups are conceptually simple: A head-node pair runs the core services like NFS and Slurm in fail-over mode (one node being active, and the other being a "hot spare" for these services, ready to take over at any moment), and, optionally, a parallel filesystem like Lustre or BeeGFS may be employed on a number of storage nodes. Such storage clusters are typically also composed of server pairs, in which each node of a pair has access to the same disks serving a set of storage targets.
So, out of frustration with the shortcomings of COPA-based clusters, the idea was born to develop a new HA stack within QluMan, providing a simple and easy-to-use HA solution, optimally fitted and tuned for exactly these use cases.
2. QHAS concepts and components
2.1. Elementary and advanced Qlustar HA setups
2.1.1. Elementary example: HPC cluster with head-nodes in HA mode
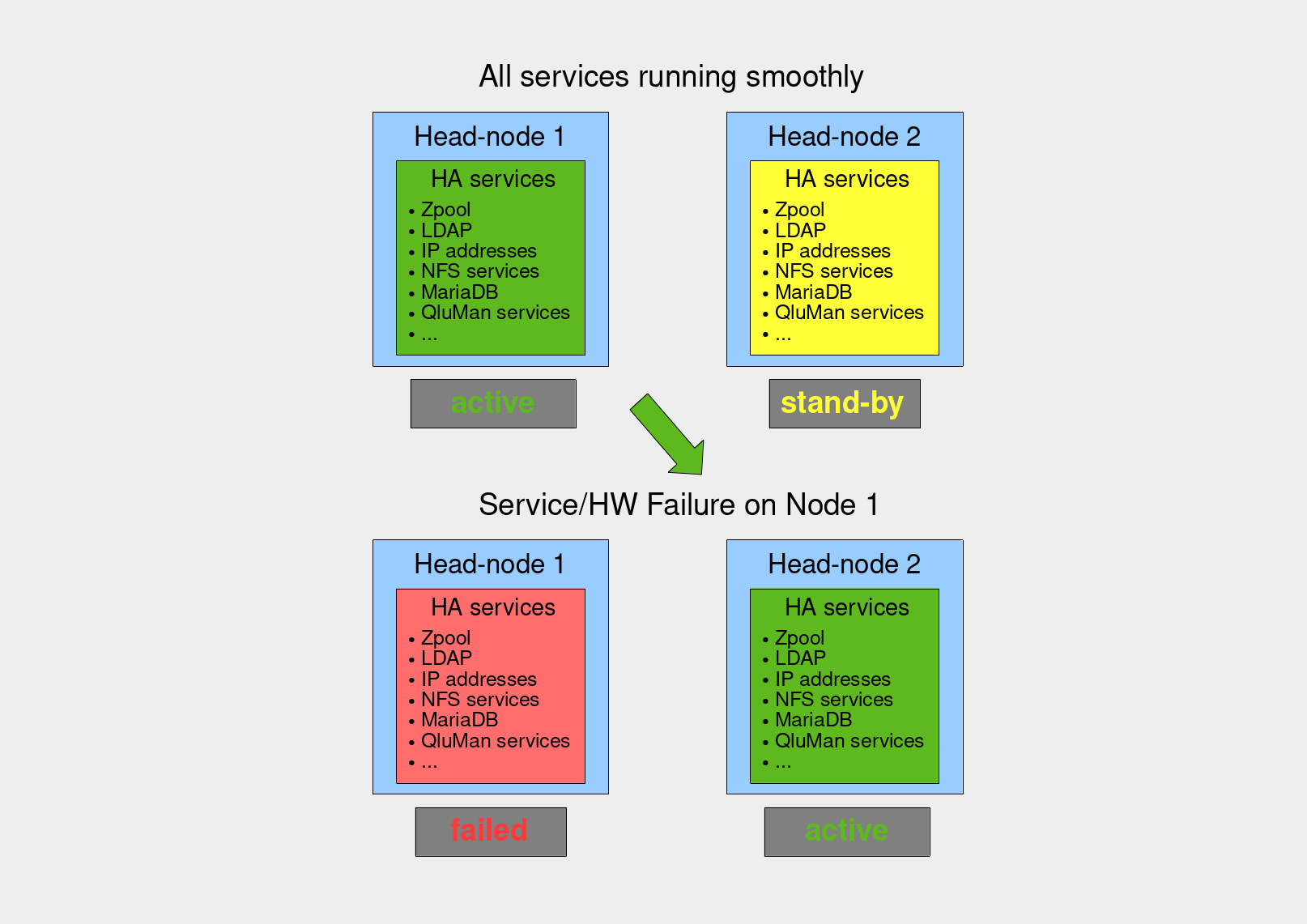
The most elementary example for a Qlustar HPC cluster with HA capability is one that has two equivalent head-nodes. The entities/services of a single standard Qlustar head-node that must be configured in a different way to achieve HA for such a setup are the following:
-
The filesystems hosting the dynamic data and state files for the services below. With QHAS, these are ZFS filesystems which are part of a ZFS pool sitting on disks shared between the two head-nodes.
-
NFS services for the filesystems to be mounted on Qlustar net-boot nodes.
-
The LDAP service.
-
The MariaDB database storing the QluMan configuration.
-
The QluMan services qlumand, qluman-dhcpscanner and optionally qluman-slurmd.
-
The Qlustar multicast daemon.
-
The Slurm services slurmdbd and slurmctld.
-
The virtual IP addresses at which these services are accessible.
Other head-node services that don’t need special treatment in HA are dnsmasq and chronyd (NTP server) since they can run on both head-nodes with identical configuration and without dynamic synchronization of their data and state files.
2.1.2. Advanced example: HPC / Storage cluster in HA mode
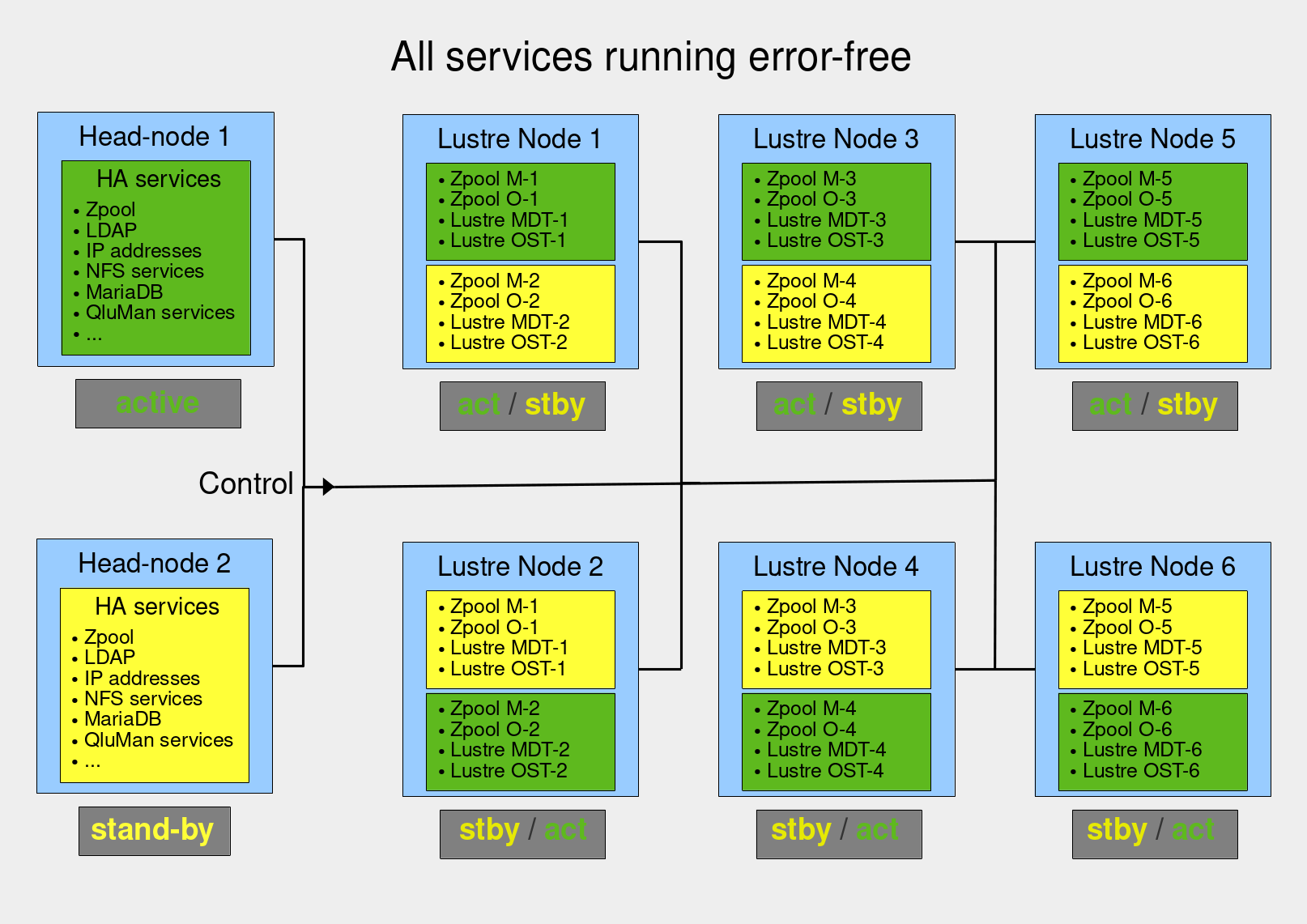
This diagram shows an example of an advanced Qlustar HPC cluster with HA capability. It consists of two head-nodes, as in the elementary case, and adds a storage cluster (serving e.g. a Lustre parallel filesystem) consisting of storage node pairs. These pairs are configured so that each node can provide all the services of its partner node.
The QHAS components running on the head-nodes are responsible for controlling and monitoring the services provided by the storage nodes. This entails sending commands for starting and stopping services, as well as migrating resources between storage nodes in case of failure. All of QHAS’s HA logic is implemented on the head-nodes; other HA nodes merely receive commands.
2.2. HA Resources and their agents
A Qlustar resource agent is an external program (usually a shell script), that is responsible for starting, stopping and monitoring a specific service and providing a consistent control interface. Such an agent is required for each type of service that is to operate in HA mode. QHAS includes a set of well-tested resource agents needed to manage Qlustar HPC and storage clusters including ones for ZFS pools, IP addresses, and generic systemd-based services.
The most atomic part of an HA setup is a so-called resource (having the same meaning in QHAS as in COPA). A resource represents a service that may be started on a node in the HA cluster; examples include ZFS pools, IP addresses, Slurm daemons, etc. Every resource in an HA setup has a name, a type, and configuration values that uniquely determine the service it represents.
2.3. Resource Groups
Various HA resources may depend on each other, and they may require starting in a certain order on the same machine. To support this, they must be tied together in a so-called resource group (RG). All the resources of an RG are started, stopped, or migrated together. When started, they are active on a single, particular HA node.
Dependencies between resources in a resource group are defined by specifying optional After and Requires lists for each resource. The After list implements a weak dependency, which means that the defined resource should be started after all of the listed resources have started. The Requires list specifies a stronger dependency, which means that the defined resource should be started after all of the listed resources have started, and also that the defined resource should be restarted if any of the listed resources are restarted.
A resource group may only run on the nodes on which its related QluMan configuration is assigned.
2.4. Core Resource Group
Every Qlustar HA setup must include a special core RG, which defines the core services and resources that are needed for the basic operation of any Qlustar HPC, AI, or storage cluster. Core services/resources are listed and described in the elementary HA example and the chapter explaining the HA setup definitions
|
The core RG is always assigned to the two head-nodes of a Qlustar HA system. Starting it on one of the head-nodes automatically makes the latter the primary one. |
|
Net-boot nodes can only boot once the core RG has started. |
2.5. HA Actions
There are 5 basic actions that can be taken. A resource or resource group can be started, stopped or restarted. A resource group can be migrated from one node to the alternate node and a node can be KOTONed to handle resources that are stuck and can’t be stopped for some reason.
|
KOTON stands for "Knock Out The Other Node". Qlustar uses this acronym to express the process of one HA node resetting one of its HA peers. We refrain from using the well-known COPA acronym STONITH describing the same thing due to the high degree of violence coming across by its literal meaning. |
From those 5 basic actions more complex actions are constructed. That way starting a resource with dependency will start the dependencies first. Or a KOTON on a node will first migrate away resources where possible. Actually restart is already made up as a stop and start and not one of the basic actions.
2.6. Automation levels
Automation levels in QHAS are a bit different than on other HA solutions and not so much levels. Above mentioned the 5 basic actions. For each of those actions the automation can be set to implicitly confirm the action or wait for the user to confirm. Actions are further split into actions taken on core resources, actions on general resources and manual actions initiated by the user themself. For each combination of the type of action and classification the confirmation can be automatic or left to the user.
|
There is no start / stop setting for core and general resources as the system will only ever create them as part of a restart, migrate or koton action. |
2.7. Role of Primary Head
With 2 head-nodes there is no good way to build a consensus for any problem as that takes at least 3 to have a majority or something. So the head-node that is running the core resources is designated as the primary head-node and always has the last word. It’s role is to manage and monitor all resources and create automatic actions to repair any failed resource.
2.8. General design principles
- Avoid unnecessary fail-overs
-
Double-check whether an error is really an error. Fail-overs are a consequence of some kind of monitoring failure. Initiate a fail-over only after multiple monitor failures.
- Rationale
-
This prevents service disruption due to unnecessary fail-overs. It is a compromise between speed of failure recovery and making sure to do the right thing. In practice, performing multiple monitor actions to confirm an error state takes additional time. This increases the duration of the fail-over process, and thereby that of the service interruption. On the other hand, it prevents unnecessary fail-overs which, by themselves, lead to some service interruption.
- Maximal control by admin
-
Highly configurable automation settings allow fine-grained admin control over which actions are automated and which ones require confirmation.
- Simplicity
-
Keep the automation logic to the bare needed minimum. Leave complex border-cases for the admin to resolve rather than risk having unwanted actions by possibly unsuitable logical assumptions.
- Transparency
-
Make it clear why an HA action happened or should happen.
3. QHAS architecture
The Qlustar High Availability System (QHAS) is a designed mainly as hot standby. There are 2 head-nodes but only the qluman-router is running on both heads at the same time in a primary/secondary configuration. All other HA resources are running on only one of a pair of nodes each with the other node as fallback. In each pair both node are equal but some nodes are more equal than others. The primary head-node is decided by where the core resources are currently running, it’s not a fixed role but switches are the core resources migrate. But one head is designated as the prefered node for the core resources, it will be used by default.
Each resource group also has two nodes with one called the preferred node. Unless otherwise specified resources are started on the preferred node. By splitting resources into separate groups and and assigning the same nodes to multiple groups load balancing can be achieved while doubling up when one node fails.
3.1. QHAS components
1) The qluman-router is the one central component that tracks the status of all resources, handles all the communications and makes all the decisions. It’s running redundant as its the one component that must not fail. It runs on the two head-nodes and both instances of the qluman-router monitor the other and keep each other in sync.
Each qluman-router is in charge of managing and monitoring its own local resources and runs commands locally. All resources on netboot nodes are managed and monitored by the primary qluman-router using the RxEngine to run commands remotely on compute nodes.
2) Netboot node can be configured to host HA resources and they, as all netboot nodes do, run qluman-execd to connect to the qluman-router and implement the RxEngine for running commands remotely. There is nothing special running on HA netboot nodes, they only need to include the HA module in their image so they have some helper scripts available locally. All the HA logic is in the qluman-router only and the RxEngine is used to manage and monitor HA resources on he netboot node with the help of the resource agent scripts.
3) The clients for interacting with the QHAS, specifically qluman-ha-cli for console access and the HA component in qluman-qt for graphical interactions. The clients give commands to the qluman-router to change the desired state of resources or change the resource configuration and the qluman-router then enacts the changes. The client is also needed to confirm qluman-router actions before they happen if the actions are not set to be confirmed automatically.
3.2. QHAS actions and confirmations
One large problem we have come across with other HA systems is that of unintended consequences. Mainly that the automation of the HA system has a run away effect when doing anything on the system and frequently takes down a node or the whole cluster due to the smalest misstep.
Other systems have a maintenance mode for this where the automation is just turned off so the system can be administered without risk of interference. The QHAS was designed to go another way. The automation can never be turned off. But each action must be confirmed before it actually runs. The system can then be configured to automatically confirm some actions implicitly but not others. This has 2 benefits over the all on/off systems:
1) The automation can be tested step by step by confirmaing each action manually. Planned actions from the automation can be checked before confirmation to be sensible and each action can be monitored and checked as it happens spearately. Or actions can be confirmed as a group and tested in parallel and when it deviates from the planned actions another confirmation will be required.
2) Automation can be finely controlled specifying what the system can do on its own and when it should wait for confirmation. Simple procedures like restarting a resource or even migrating a resource group can be set to happen automatically while invoking KOTON on a node can be set to require manual confirmation. By setting what the system can and can not do any run away effect can be stopped and the system won’t escalate into taking down the whole cluster accidentally.
The automation settings can be stored as presets with 2 presets created by default: Maintenance and Automatic. By default the Maintenance settings are to only allow the start of resources without manual confirmation while Automatic allows all actions the QHAS system can take on it’s own.
|
The need for confirmation even extends to manual actions the user takes in the graphical frontend. It’s easy to click on some node and the KOTON button while overlooking that some resources are running on the node. So hitting the KOTON button creates the neccessary actions on the qluman-router and then asks the user to confirm them. Even in the Automatic preset the manual actions other than resource start are still set to require confirmation but this can be changed if desired. |
4. Defining the HA setup
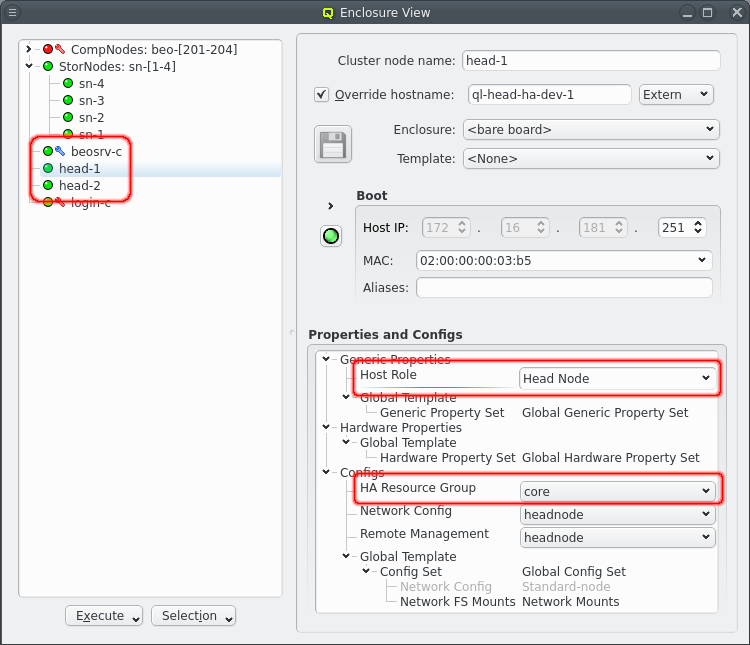
In Qlustar a HA setup requires exactly 2 physical and one virtual head-node. The two physical head-nodes which will run in a primary / secondary configuration. The primary head-node is in full control of the cluster and runs all the core resource and services for the cluster and will act as the virtual head-node for the cluster. The secondary head-node just follows along ready to take over on a seconds notice, which will make it the new primary head-node. In Qluman the head-nodes are defined by having the generic property Host Role set to Head Node. They also have the core Resource Group assigned to the physical head-nodes but not to the virtual head-node beosrv-c.
4.1. Core resources
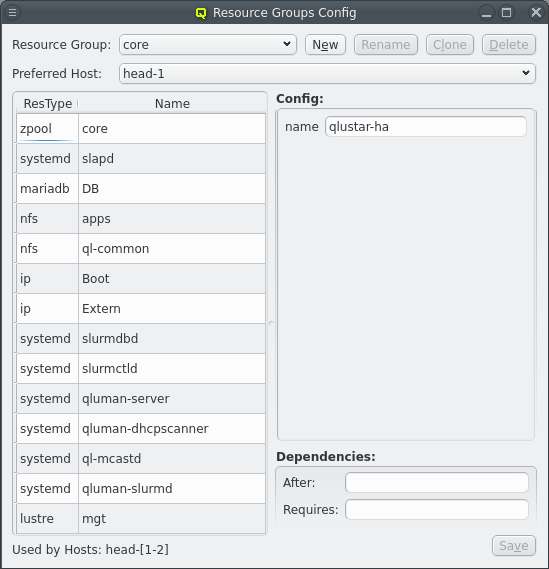
A Qlustar cluster has a number of essential resources and services that are required for netboot nodes to be able to boot and function. These resources are predefined when initializing the HA cluster and hopefully require little to no changes. None the less they can be customized as shown in the next chapter. But first these are the core resources:
-
zpool:core
The HA setup requires shared storage between the 2 head-nodes so that the primary head-node always has the same set of configuration and runtime data regardless on which head-node the core resource are running. The shared storage is formated with ZFS and the zpool:core resource manages importing and exporting the zfs pool.
-
nfs:apps and nfs:ql-common
Per default 2 NFS shares are exported for the use by netboot nodes. The nfs:apps resource holds the chroots used for installing additional software for compute nodes and local software as well as the homedirs for users on smaller clusters. On larger clusters homedirs can be on separate NFS exports, Lustre or BeeGFS filesystems. The nfs:ql-common resource holds common config files shared with all nodes that are mostly private to qlustar.
-
ip:Boot and ip:Extern
To achieve a seemless failover clients connect to core services via virtual IPs. Meaning the two head-nodes have their physical IPs but there is also a 3rd set of IPs that is used by clients to connect to the current primary head. On failover those virtual IPs are transfered from the old primary to the new primary. This allows for example the seemless failover of the NFS shares above. ip:Boot manages the IP for the boot network and ip::Extern manages the IP for the external network. Depending on the network configuration additional IP resources may need to be added.
-
mariadb:DB and systemd:* services
All the Qluman configuration data for the cluster and nodes are kept in a MariaDB among other databases (e.g. Slurm if used). The mariadb:DB resource manages this instance of MariaDB. The systemd:* resources match the respective systemd *.service files and manage starting, stopping and monitoring those services. For LDAP there is the systemd:slapd resource to manage the Qlustar LDAP server. For Qluman there is the main server systemd:qluman-server that manages all the configuration of nodes in the cluster and the cluster as a whole. It also has 2 helper in the systemd:ql-mcastd and systemd:qluman-dhcpscanner resources.
-
Slurm
If slurm is used then 3 additional resources are present: systemd:slurmdbd, systemd:slurmctld and systemd:qluman-slurmd, which just bring up the respective daemons. qluman-slurmd is the bridge between the slurm daemon and qluman-qt for configuring slurm via the GUI.
-
Lustre
For clusters using storage nodes with Lustre there is one last resource that will be added: lustre:mgt. This manages the Lustre Management service from which all storage nodes and clients fetch their lustre config. Given the minimal storage and cpu requirements and to provide redundancy this is included in the head-nodes instead of it’s own server.
4.2. Configuring resources and setting defaults
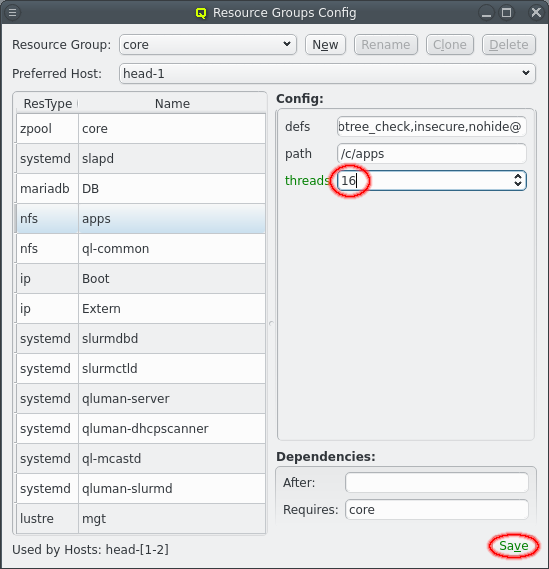
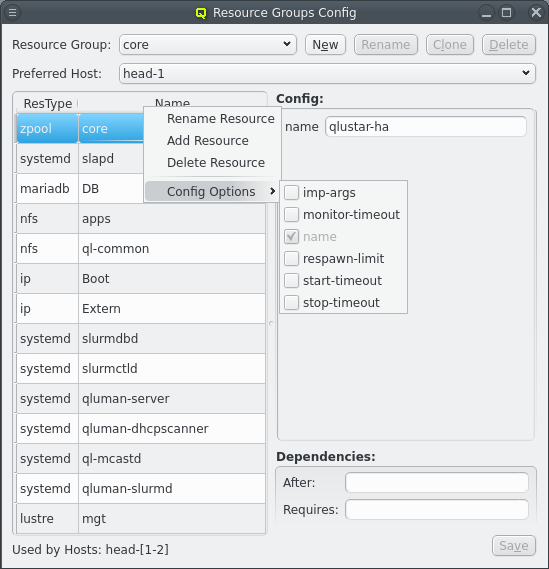
HA Resource Groups can be configured by opening the [Resource Group Config] window. At the top a resource group can be selected. The resources for the selected resource group are then shown at the left. Selecting a resource will show the configuration for the resource at the right.
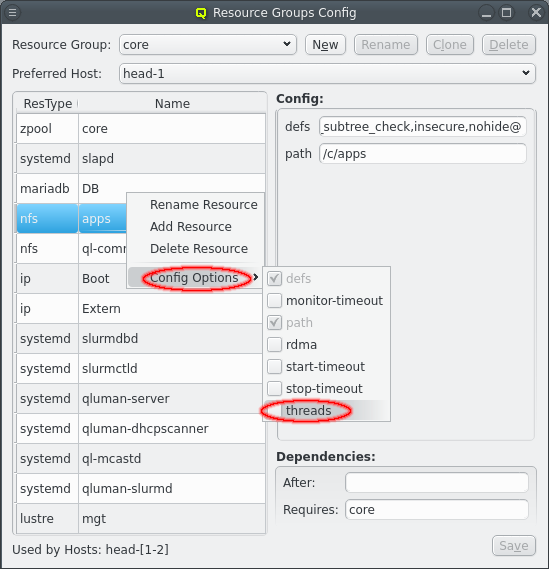
Each resource has a resource type that corresponds to an agent script to manage resource of that type and a name to uniquely identify the resource. For example NFS shares use the nfs agent. The agent scripts define the config options the agent accepts, their type, and optional limits and default values. Config options without default value must be defined for each resource, for example the exported path for NFS resources. Those will always be shown when selecting the resource. To edit an option click on the text for an option and edit it. For numerical values up and down arrows are included to lower or raaise the value. To finalize the change click the Save button. Config options with default values are considered optional and are not shown per default. To change the config option from their default the option must first be added to the resource by selecting it from the menu:[Config Options] context menu for that resource. The option can then be changed like other options.
Changes to the HA Resource Groups don’t take immediate effect. So there is no risk of disrupting a working cluster when changing the configuration. Once the configuration is finished it must be finalized by writing the High Availability file class in the Write Files window. The Write Files will be active when you have unwritten changes same as with other file classes.
|
For larger changes in the HA setup, e.g. adding new resources, it is recommended to switch to mainainance mode or at least disable automatic KOTON in the HA Status Window. This way the changes can be tested by going through start, stop, migrate manually without the automation escalating a small configuration error into reseting hosts. |
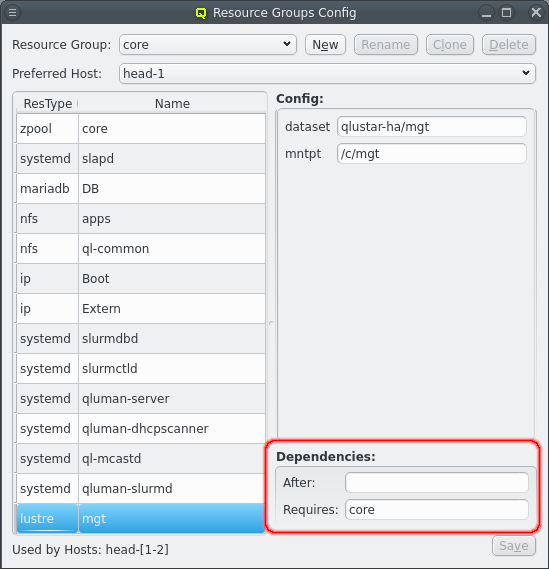
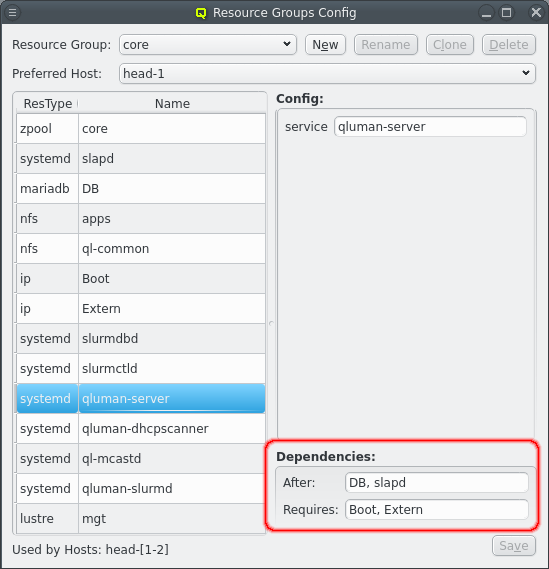
On the bottom right the dependencies for the selected resource are shown. Dependencies determine the order in which resources are started or stopped. Generally when resource X depends on resource Y then X will be started only after Y is running. And Y will be stopped only when X has been stopped.
Dependencies are split into 2 groups: After and Requires. Using Requires is the safe choice but After is the preferred choice because it allows for a simpler and faster error recovery. Both act the same when doing a start, stop, migrate or koton action. When X depends on Y then X waits for Y to be online before X is started and Y waits for X to be offline before Y is stopped. The difference is the behavior when a resource is restarted. For restarts the After dependencies are ignored which limits the effect of recovering from an error. With Requires on the other hand everything requiring X is also restarted when X is restarted due to either minitoring failure or manual action.
As example the qluman-server resource is set to After DB and slapd but Requires Boot and Extern. All 4 resources must be running before qluman-server is started. But DB or slapd can be restarted without affecting qluman-server since qluman-server will simply reconnect to them automatically. On the other hand if the Boot or Extern IPs are restarted the qluman-server needs to be restarted as well as it does not recover from loosing the network connection.
Another example is the Lustre mgt. Since it accesses data on the core zpool it needs a dependency on core. But the zpool can not be restarted as long as something accesses the pool. Mgt must therefore declare a Requires dependency. When zpool is to be restarted then first mgt is stopped, then zpool is restarted and finally mgt is started again.
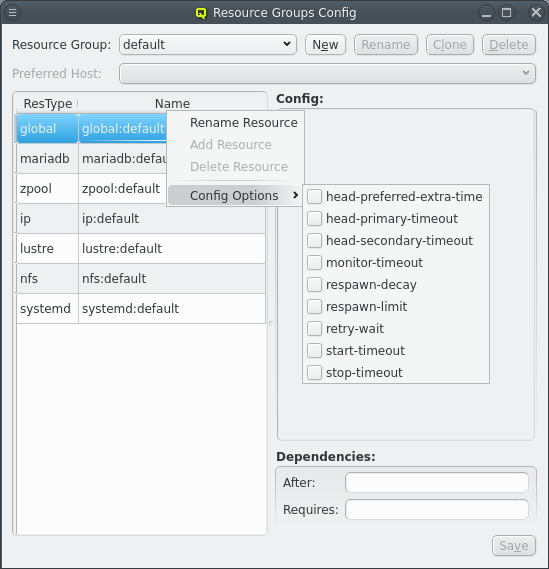
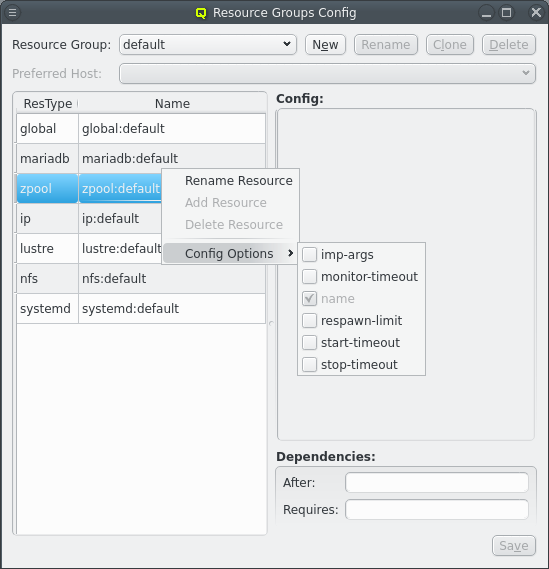
There are often multiple resources of the same type and some config options, especially the timeouts, are often the same for all resources of a certain type or even system wide. These options almost always come with a default provided by the agent and don’t have to be set for any resource. None the less the default value might not be suitable. Setting the same value for every resource would be repetitive. Qluman-qt therefore provides another way to set reoccuring options by means of the default resource group.
The resources in the default group have none of the required options, in fact their config is all empty per default. But just like with the core resources optional config options can be added via the menu:[Config Options] context menu and edited in just the same way. This then changes the value for all resources of the same resource type unless overwritten in the resource itself. The global:default entry has an even wider range as it sets default values for all agents as well as a few timeout options for the head-nodes.
4.3. Creating additional RGs
The core resource group is there to manage the basic resources required to configure and boot all other hosts. Everything not related to those jobs should be in their own resource groups. To create a new resource group click the New button and enter the name of the new resource group. After creation the new resource group will automatically be selected. For resource groups other than core the Rename, Clone and Delete, assuming the resource group is not in use by any host, will be enabled. Rename allows changing the name of a resource group and Delete allows deleting an unused resource group. The Clone is described below in more detail.
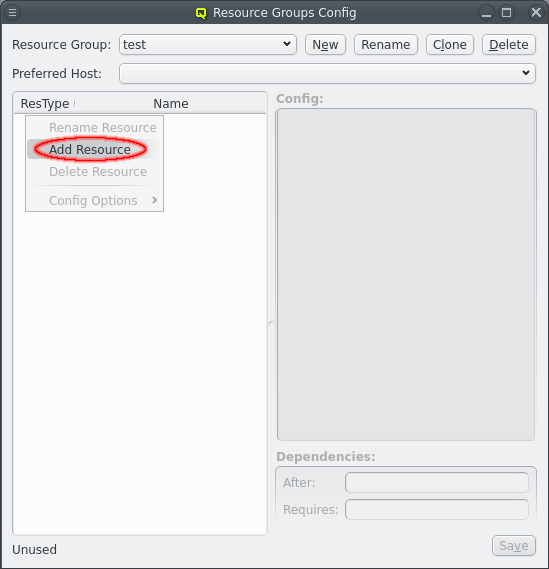
The newly created resource group is without any resources. To add resources open the context menu in the resource table on the left and select menu:[Add Resource]. Enter the name for the new resource in the Add Resource dialog and select the resource type. If the name is unique the OK button can be selected to create the resource.
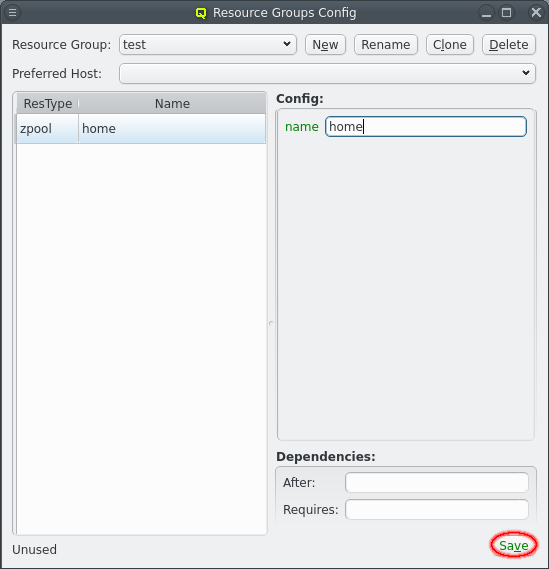
Select the new resource to show the config options for the resource at the right. All the required options will be present for the resource but lacking values. These must be filled in and show a green label when the value is acceptable. A red label is shown when the input is impossible and a yellow label when the input is possible but incomplete. When all the required fields have been filled in click the Save button to save the values.
Don’t forget to also conifgure any After or Requires dependencies between the resources. Dependencies are only between resources within a resource group so every resource that depends on another must be in the same resource group. Whenever resources aren’t dependent on each other, directly or indirectly, it is recommended to put them in different resource groups. The resource group should form a single unit of related resources. This give the maximum flexibility for error recovery, migrating resources and balancing the load across multiple servers.
|
After creating a resource group don’t forget to assign the resource groups to a pair of hosts. |
4.4. Cloning resource groups
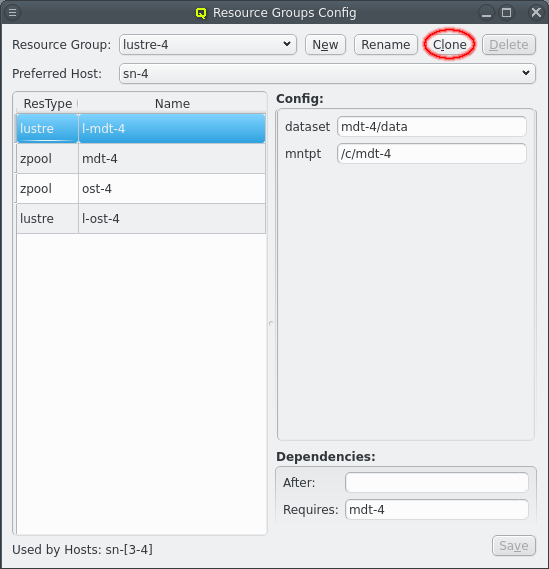
Distributed storage can quickly require a number of repetitive Resource Groups. The Resource Groups will have the same Resources and Resource configs with minor changes. Optiomally, for the ease of configuration, those difference are just a change in a number. The above shows an example for a storage setup with 4 storage nodes running 4 Lustre MDT and OST instances to make one large Lustre filesystem. The Resource Groups are numbered from lustre-1 to lustre-4. Each Resource Group has 4 resources for the respective ZFS storage and lustre MDT/OST setup, again numbered from 1 to 4.
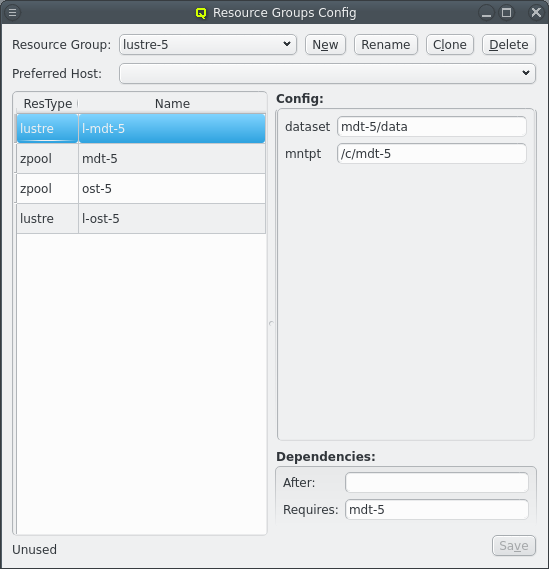
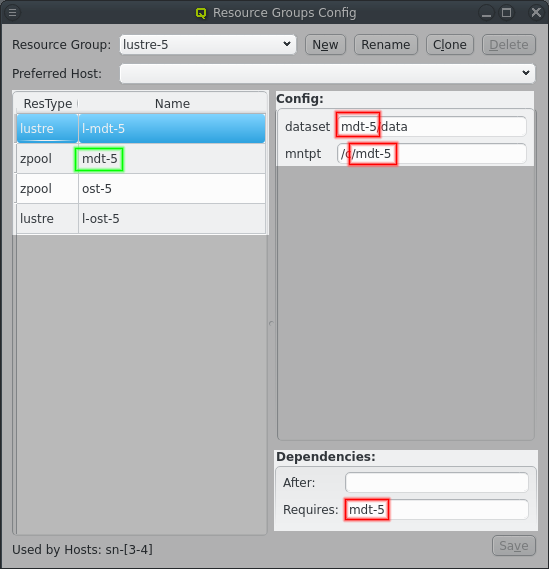
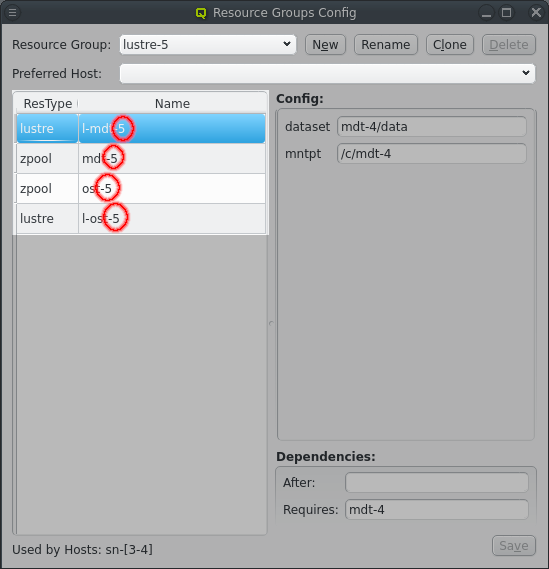
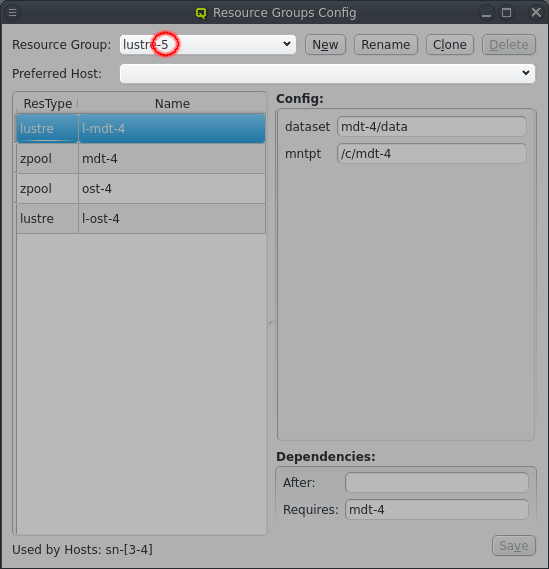
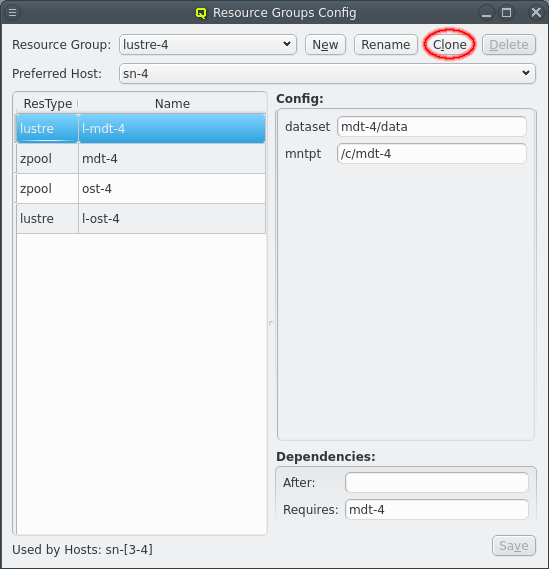
Numbering the Resource Groups and Resources like this makes creating them a breeze. First a Resource Group has to be created ending in a number, usually "1" for small sets or "01" for larger sets. Using a matching number in the names for Resources and in config options helps in the the next step, which is clicking the Clone button. This create a new Resource group from the selected Resource Group following a few steps to adjust the Resources and Resource configurtion.
The first step is to increment the name of the Resource Group to create a new unique name by incrementing the trailing number in the name. Extra digits are added to the number as needed.
The second step is to increment the name of Resources to give unique Resource names. The number used in Resource names doesn’t have to match the number in the Resource Group name as it is simply incremented until a new unique name is found. But it is recommended to use matching numbers to make the connection between Resource and Resource Group obvious.
The thrid and last step is to update the config for each Resource. Any time the name of a Resource appears in the config option the substring is replaced with the name of the new Resource. Similar dependencies on the old name are changed to the new name.
This process can be repeated as many times as needed to quickly create all the repetitive Resource Groups. Simply select one of the existing Resource Groups and click the Clone again. Finally adjust any Resources that follow a simple numbering scheme or Resource options where more than a replacement of the resource name is needed.
|
The Clone button replaces occurances of Resource names in the config options. This usually does the right thing. But depending on the names and values of options used it can also go wrong. Resource names should be picked to avoid accidental matches with values used in options when the clone feature is to be used. |
4.5. Assigning RGs to nodes and preferred hosts
After a resource group has been created it has nowhere to run. For Qluman to know where the resource group should run the resource group needs to be assigned to a pair of hosts. To do this open the and select the two nodes. Then add the resource group by selecting it from the context menu.
Once a resource group has been assigned to hosts the respective hosts will be listed at the bottom right of the Resource Groups Config widget. It also becomes possible to select a preferred host for the resource group.
A resource group should always be assigned to 2 hosts. One is the preferred hosts for the group, which simpply means the host the resource group will be started on per default, when not specifying a host to start the resource group on. The second host is the fallback in case the preferred host has an error. Per default the alphanumerically first host is the preferred host.
Since the fallback host for any one resource group is normally just sitting there idle it is common to have 2 resource groups assigned to each pair of hosts in a HA setup. The idea is to run one resource group on each host under normal operation. But when a host fails the other host takes over and runs both resource groups with potentially reduced performance. For this configuration the preferred host for one of the resource groups should be changed so they start in the distributed setup per default.
5. Operating the HA cluster
After a cold start of the cluster the qluman router, and therefore the HA system, does not automatically start. This allows the admin to check each head-node has properly booted and is ready before the HA system is let loose. The main thing to check is that the iSCSI connctions have reconnected so the shared storage does not needlessly enter a degraded mode. The router can then be started via command line by running systemctl start qluman-router on both head-nodes.
Once the router is running the HA cluster can be interacted with from the command line using qluman-ha-cli or using the graphical interface in Qluman Qt. In either case the startup procedure is to first start the core Resource Group. This then allows other nodes in the cluster to boot. Additional HA nodes can then be set active and additional HA Resource Groups can be started.
5.1. qluman-ha-cli
The command line interface to the HA cluster is called qluman-ha-cli. It provides a non-interactive interface to the HA system allowing the user to check the status of the cluster, modify the automation settings by selecting different presets, manipulate the state of resources and resource groups and confirm or reject pending actions.
0 root@ql-head-ha-dev-1 ~ #
qluman-ha-cli --help
usage: qluman-ha-cli [-h] [-c CONFDIR]
(--status | --set-offline SET_OFFLINE [SET_OFFLINE ...] | --start START [START ...] | --stop STOP [STOP ...] | --restart RESTART [RESTART ...] | --migrate MIGRATE [MIGRATE ...] | --confirm CONFIRM [CONFIRM ...] | --reject REJECT [REJECT ...] | --preset PRESET | --clear CLEAR [CLEAR ...] | --activate ACTIVATE [ACTIVATE ...] | --deactivate DEACTIVATE [DEACTIVATE ...] | --koton KOTON [KOTON ...])
[--hard] [--node NODE] [--monitor] [--verbose]
options:
-h, --help show this help message and exit
-c CONFDIR, --confdir CONFDIR
Directory where qluman configuration files are located
--status Show status of HA resources
--set-offline SET_OFFLINE [SET_OFFLINE ...]
Set node offline
--start START [START ...]
Start HA resource or group
--stop STOP [STOP ...]
Stop HA resource or group
--restart RESTART [RESTART ...]
Restart HA resource or group
--migrate MIGRATE [MIGRATE ...]
Migrate HA group
--confirm CONFIRM [CONFIRM ...]
Confirm pending action
--reject REJECT [REJECT ...]
Reject pending action
--preset PRESET Activate automation preset
--clear CLEAR [CLEAR ...]
Clear Action log
--activate ACTIVATE [ACTIVATE ...]
Activate an HA netboot node or clear error state from any node
--deactivate DEACTIVATE [DEACTIVATE ...]
Deactivate an HA netoboot node
--koton KOTON [KOTON ...]
KOTON HA nodes
--hard Set KOTON to power off hard
--node NODE Select node for start action
--monitor Monitor actions
--verbose Show more details for actions
The amount of options might seem overwhelming at first but most are actions that fall into one of a few groups.
5.1.1. Status of the cluster
The simplest action is to display the current status of the cluster using --status. This will first display the current automation settings and available automation presets. Next a list of all HA nodes, their KOTON (or power management) status, their HA status and last a list of resource groups configured for the node. That is followed by one section for each resource group listing the groups node associations and resource status. Last is a section for pending or running actions, if any. For a freshly booted cluster with the routers started on both head-nodes this looks like this:
0 root@ql-head-ha-dev-1 ~ #
qluman-ha-cli --status
Automation: core = [], general = [], manual = ['start']
Mail Alerts: True
Presets: Maintenance, Automatic
Nodes:
head-1 [KOTON online] [Status online]: core
head-2 [KOTON online] [Status online]: core
sn-1 [KOTON offline] [Status unknown]: lustre-1 lustre-2
sn-2 [KOTON offline] [Status unknown]: lustre-1 lustre-2
sn-3 [KOTON offline] [Status unknown]: lustre-3 lustre-4
sn-4 [KOTON offline] [Status unknown]: lustre-3 lustre-4
Group core
Nodes: head-1 head-2
Preferred Node: head-1
Current Node: None
zpool:core offline
nfs:apps offline
nfs:ql-common offline
ip:Boot offline
ip:Extern offline
lustre:mgt offline
mariadb:DB offline
systemd:ql-mcastd offline
systemd:slapd offline
systemd:qluman-server offline
systemd:qluman-dhcpscanner offline
systemd:slurmdbd offline
systemd:slurmctld offline
systemd:qluman-slurmd offline
Group lustre-1
Nodes: sn-1 sn-2
Preferred Node: sn-1
Current Node: None
zpool:mdt-1 unknown
lustre:l-mdt-1 unknown
zpool:ost-1 unknown
lustre:l-ost-1 unknown
When any actions are pending or currently running they are listed at the end:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = [], general = [], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic Nodes: ... Actions: 2024 Sep 22 16:41:50 ┗┳━ [195 waiting] Repair for Resource Group 'core' 2024 Sep 22 16:41:48 ┣━━ [197 success] probe resource zpool:core 2024 Sep 22 16:41:48 ┣━━ [199 success] probe resource lustre:mgt 2024 Sep 22 16:41:50 ┣━━ [201 success] probe resource mariadb:DB 2024 Sep 22 16:41:48 ┣━━ [203 success] probe resource nfs:apps 2024 Sep 22 16:41:48 ┣━━ [205 success] probe resource nfs:ql-common 2024 Sep 22 16:41:48 ┣━━ [207 success] probe resource systemd:slapd 2024 Sep 22 16:41:48 ┣━━ [209 success] probe resource ip:Boot 2024 Sep 22 16:41:48 ┣━━ [211 success] probe resource ip:Extern 2024 Sep 22 16:41:48 ┣━━ [213 success] probe resource systemd:ql-mcastd 2024 Sep 22 16:41:50 ┣━━ [215 success] probe resource systemd:qluman-server 2024 Sep 22 16:41:50 ┣━━ [217 success] probe resource systemd:slurmdbd 2024 Sep 22 16:41:50 ┣┳━ [219 unconfirmed] Event restart resource 'systemd:qluman-dhcpscanner' 2024 Sep 22 16:41:50 ┃┗━━ [221 unconfirmed] stop resource systemd:qluman-dhcpscanner 2024 Sep 22 16:41:50 ┣━━ [223 success] probe resource systemd:slurmctld 2024 Sep 22 16:41:50 ┗━━ [225 success] probe resource systemd:qluman-slurmd
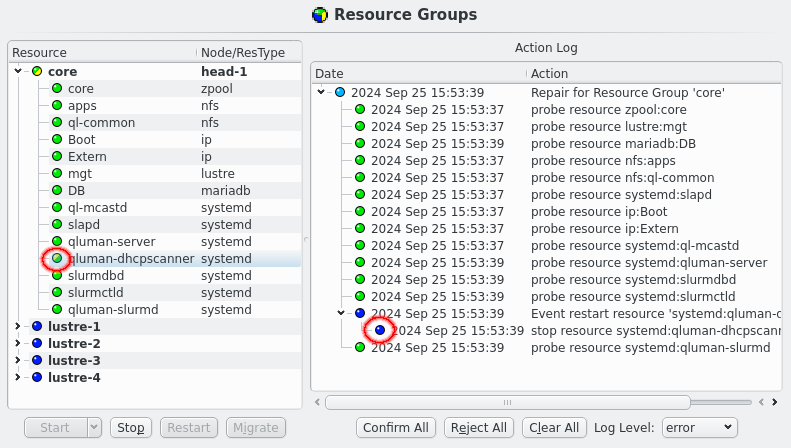
Here is an example of qluman-dhcpscanner having failed. The monitoring of the resource fails and initiates a repair action. A failure of a resource can be due to one of it’s dependencies or the underlying reason for one resource failing will affect other resources the same way. The repair action therefore checks all the resources of the resource group in order of dependencies. So while in this example only qluman-dhcpscanner was killed as a test the repair action shows all the other resources of the core resource group being probed.
In the output each line shows one action starting with the time of the actions last activity and a tree representation of the relationship between actions. Larger actions like a repair is split into separate smaller actions like the resource probes. This can happen recursively until every action is split into a single command as can be seen with the restart Event.
Each action keeps a log of the individual steps involved in processing the action. The log can be included in the status display if the --verbose option is also specified. The above example with --verbose looks like this:
Actions: 2024 Sep 22 16:41:50 ┗┳━ [195 waiting] Repair for Resource Group 'core' 2024 Sep 22 16:41:48 ┃ info Repair for Resource Group 'core' triggered by Resources 'systemd:qluman-dhcpscanner' 2024 Sep 22 16:41:48 ┣━━ [197 success] probe resource zpool:core 2024 Sep 22 16:41:48 ┃ info Resource:Command:zpool:core:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n core -t zpool' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [199 success] probe resource lustre:mgt 2024 Sep 22 16:41:48 ┃ info Resource:Command:lustre:mgt:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n mgt -t lustre' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:50 ┣━━ [201 success] probe resource mariadb:DB 2024 Sep 22 16:41:48 ┃ info Resource:Command:mariadb:DB:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n DB -t mariadb' 2024 Sep 22 16:41:50 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [203 success] probe resource nfs:apps 2024 Sep 22 16:41:48 ┃ info Resource:Command:nfs:apps:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n apps -t nfs' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [205 success] probe resource nfs:ql-common 2024 Sep 22 16:41:48 ┃ info Resource:Command:nfs:ql-common:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n ql-common -t nfs' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [207 success] probe resource systemd:slapd 2024 Sep 22 16:41:48 ┃ info Resource:Command:systemd:slapd:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n slapd -t systemd' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [209 success] probe resource ip:Boot 2024 Sep 22 16:41:48 ┃ info Resource:Command:ip:Boot:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n Boot -t ip' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [211 success] probe resource ip:Extern 2024 Sep 22 16:41:48 ┃ info Resource:Command:ip:Extern:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n Extern -t ip' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:48 ┣━━ [213 success] probe resource systemd:ql-mcastd 2024 Sep 22 16:41:48 ┃ info Resource:Command:systemd:ql-mcastd:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n ql-mcastd -t systemd' 2024 Sep 22 16:41:48 ┃ info finished with 0 2024 Sep 22 16:41:50 ┣━━ [215 success] probe resource systemd:qluman-server 2024 Sep 22 16:41:50 ┃ info Resource:Command:systemd:qluman-server:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n qluman-server -t systemd' 2024 Sep 22 16:41:50 ┃ info finished with 0 2024 Sep 22 16:41:50 ┣━━ [217 success] probe resource systemd:slurmdbd 2024 Sep 22 16:41:50 ┃ info Resource:Command:systemd:slurmdbd:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n slurmdbd -t systemd' 2024 Sep 22 16:41:50 ┃ info finished with 0 2024 Sep 22 16:41:50 ┣┳━ [219 unconfirmed] Event restart resource 'systemd:qluman-dhcpscanner' 2024 Sep 22 16:41:50 ┃┗━━ [221 unconfirmed] stop resource systemd:qluman-dhcpscanner 2024 Sep 22 16:41:50 ┣━━ [223 success] probe resource systemd:slurmctld 2024 Sep 22 16:41:50 ┃ info Resource:Command:systemd:slurmctld:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n slurmctld -t systemd' 2024 Sep 22 16:41:50 ┃ info finished with 0 2024 Sep 22 16:41:50 ┗━━ [225 success] probe resource systemd:qluman-slurmd 2024 Sep 22 16:41:50 info Resource:Command:systemd:qluman-slurmd:monitor: starting '/usr/lib/qlustar/HA/bin/manage-resource --checksum 3abbe5fe28ceb9f376bbcb27ee0e39d954cb7e72c99c51e49621a04004bd14bd -a monitor -n qluman-slurmd -t systemd' 2024 Sep 22 16:41:50 info finished with 0
The same information is also mirrored in the router log files but there it is in a flat list showing everything that happened sorted by time and picking out the relevant lines for a specific action is difficult.
Each log entry for an action starts with a severity level. In the above case all entries have the info level. Other levels are error, stderr, stdout, debug and trace. Info and error levels show what’s going on with the action on a high level. The stderr and stdout levels corresponds with the output of commands that are executed and can be helpful in understanding why a command executed for a resource failed. The debug and trace levels are basically useless without internal knowledge or following the code path in the source and it’s probably best to ignore those.
|
In qluman-qt in the HA Status Widget the log level for actions can be chosen so that only entries with a higher or equal level are shown. It’s recommended to use that instead of qluman-ha-cli to browse the log entries as the all or nothing approach is a bit overwhelming. |
5.1.2. Manipulating Resources and Resource Groups
The actions to manipulate resource and resource groups are: --start. --stop, --restart and --migrate. In a way also --koton but that is covered in the next chapter about manipulating nodes. The first three action can be used on resources or resource groups while migrate always requires a resource group since all actions of a resource group must run on the same node. Following the action a list of resources or resource groups must be specified. Specifying a resource group in an action is equivalent with listing all resources of the resource group individually. As a special alias all can also be specified to, as the name says, act on all resources.
|
All can not be used all the time as some actions come with requirements. For example resource groups can only be started when they have a node in online state. Trying a start action on all when nodes are offline then fails overall. On the other hand a --stop all will work even if some resources or whole resource groups are already stopped. |
As the names imply --start is used to start resources and --stop to stop resources. This will honor the dependencies of resources, both required and after. A little more complex is --restart as it will first stop resources in order of the required dependency and then start them back up. The after dependencies are ignored. One step further is --migrate, which will stop the resource group on one node and start it again on the alternate node.
Per default actions in qluman-ha-cli initiate the action and confirm their execution ignoring the automation settings for manually actions. This is unlike the behavior of qluman-qt as it is assumed that typing in the full name of a resource or resource group is hard enough to as it is while button is too easy to click accidentally. Also this allows qluman-ha-cli to be used in scripts. Users should be aware that there is no safety net with qluman-ha-cli.
After initiating the action and confirming it’s execution qluman-ha-cli simply returns:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --start core
A successful return only means the action has been started. It’s execution is still ongoing and might still fail. The progress of the action can be checked using the --status action.
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = [], general = [], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic Nodes: ... Actions: 2024 Sep 22 17:47:50 ┗┳━ [527 waiting] Event Stop Resource Groups 2024 Sep 22 17:47:50 ┗┳━ [529 waiting] Event Stop Resource Group 'core' 2024 Sep 22 17:47:52 ┣━━ [531 running] stop resource ip:Boot 2024 Sep 22 17:47:50 ┣━━ [533 success] stop resource systemd:ql-mcastd 2024 Sep 22 17:47:52 ┣━━ [535 success] stop resource systemd:qluman-server 2024 Sep 22 17:47:51 ┣━━ [537 success] stop resource systemd:qluman-dhcpscanner 2024 Sep 22 17:47:51 ┣━━ [539 success] stop resource systemd:slurmdbd 2024 Sep 22 17:47:51 ┣━━ [541 success] stop resource systemd:slurmctld 2024 Sep 22 17:47:51 ┣━━ [543 success] stop resource systemd:qluman-slurmd 2024 Sep 22 17:47:52 ┣━━ [545 running] stop resource ip:Extern 2024 Sep 22 17:47:50 ┣━━ [547 running] stop resource lustre:mgt 2024 Sep 22 17:47:53 ┣━━ [549 success] stop resource mariadb:DB 2024 Sep 22 17:47:50 ┣━━ [551 waiting] stop resource nfs:apps 2024 Sep 22 17:47:50 ┣━━ [553 waiting] stop resource nfs:ql-common 2024 Sep 22 17:47:52 ┣━━ [555 success] stop resource systemd:slapd 2024 Sep 22 17:47:50 ┗━━ [557 waiting] stop resource zpool:core
Actions are executed in order of dependencies. A waiting state signals that one or more dependencies of an action still need to complete. But actions are executed in parallel as much as the dependencies allow. So it’s not uncommon to have multiple actions in running state.
When everything works fine actions can execute and finish quickly and trying to catch them in the action as they change with the --status command is hit and miss. Instead --monitor option can be used to tell qluman-ha-cli to wait for an action to complete and to display resource and resource group changes as they happen:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --start core --monitor Connected to router Starting resource groups core Action started with id 423 Resource ip:Boot: status = offline Resource ip:Extern: status = offline Resource lustre:mgt: status = offline Resource mariadb:DB: status = offline Resource nfs:apps: status = offline Resource nfs:ql-common: status = offline Resource systemd:ql-mcastd: status = offline Resource systemd:qluman-dhcpscanner: status = offline Resource systemd:qluman-server: status = offline Resource systemd:qluman-slurmd: status = offline Resource systemd:slapd: status = offline Resource systemd:slurmctld: status = offline Resource systemd:slurmdbd: status = offline Resource zpool:core: status = offline Resource zpool:core: status = starting Group core: current_node = head-1 Resource zpool:core: status = online Resource nfs:ql-common: status = starting Resource lustre:mgt: status = starting Resource mariadb:DB: status = starting Resource systemd:slapd: status = starting Resource nfs:apps: status = starting Resource systemd:slapd: status = online Resource lustre:mgt: status = online Resource nfs:apps: status = online Resource nfs:ql-common: status = online Resource ip:Extern: status = starting Resource ip:Boot: status = starting Resource mariadb:DB: status = online Resource ip:Boot: status = online Resource ip:Extern: status = online Resource systemd:ql-mcastd: status = starting Resource systemd:qluman-server: status = starting Resource systemd:slurmdbd: status = starting Resource systemd:ql-mcastd: status = online Resource systemd:qluman-server: status = online Resource systemd:qluman-dhcpscanner: status = starting Resource systemd:slurmdbd: status = online Resource systemd:slurmctld: status = starting Resource systemd:slurmctld: status = online Resource systemd:qluman-slurmd: status = starting Resource systemd:qluman-dhcpscanner: status = online Resource systemd:qluman-slurmd: status = online
There is one extra option that applies to the --start action and that is --node. Per default resources and resource groups are started on their preferred node, assuming the resource group doesn’t already have a current node because another of it’s resources is running. To start a resource or resource group on the alternate node the node must be specified using --node.
5.1.3. Manipulating nodes
There are also actions to manipulate nodes instead of resources or resource groups. The first of those is --set-offline. This is a special action to tell the HA system that a node is unavailable and does not have any resources running on it. It is only applicable to nodes in the unknown state and saves the HA system to wait for timeouts and to KOTON unreachable nodes. Most notable this is useful when starting the cluster with only one head-node.
The next two actions are --activate and --deactivate. The first application of this is for netboot nodes. When a netboot HA node boots it enters the inactive state:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = [], general = [], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic Nodes: head-1 [KOTON online] [Status online]: core head-2 [KOTON online] [Status online]: core sn-1 [KOTON online] [Status inactive]: lustre-1 lustre-2 sn-2 [KOTON online] [Status inactive]: lustre-1 lustre-2 sn-3 [KOTON online] [Status inactive]: lustre-3 lustre-4 sn-4 [KOTON online] [Status inactive]: lustre-3 lustre-4
This means the node has successfully booted, the remote execution engine is up and running and the node is ready to handle resources. But in case iSCSI still needs some more time to settle or the node was booted up for diagnostic reasons it is not automatically cleared for HA use. This can be done with the --activate action. The --deactivate action does the opposite and declares the node no longer suitable for HA resources.
There is also a second use case for --activate. When a resource on a node experiences problems that are not resolved by restarting the resource then the node is put into an error state and the affected resource group is migrated to it’s alternate node. This prevents resources from migrating to the suspect node, most importantly the resource that has just been migrated away is prevented from going back and forth over and over if it fails on both nodes. The --activate command is used to clear the error state of a node, including head-nodes.
The last action related to nodes is --koton. This is the big brother to migrate. This will stop all resources on the named nodes, power cycle the node and then start the resource groups on their alternate node(s). Due to the power cycle this also works when resources can’t be stopped and it’s exactly for that use case that it exists.
When using just --koton the router attempts to stop the resources running on the specified nodes. In cases just some resources can’t be stopped this still shuts down the other resources on the node cleanly. For cases where this is known to be pointless, for example when the zpool required by all resources failed and none can be stopped, the --hard option can be added. This will skip the attempt to stop resources and immediately power cycle the node.
5.1.4. Manipulating actions
So far all the commands have been for initiating actions like starting a resource and qluman-ha-cli automatically confirms those actions so they immediately are executed. Not so when starting actions via qluman-qt or when the automation initiates repair actions on it’s own. In both of those cases the automation settings are consulted to see if an action should wait for confirmation or execute immediately.
As previously mentioned the --status command will show pending actions:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = [], general = [], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic ... Actions: 2024 Sep 22 19:06:27 ┗┳━ [709 waiting] Repair for Resource Group 'core' 2024 Sep 22 19:06:25 ┣━━ [711 success] probe resource zpool:core 2024 Sep 22 19:06:25 ┣━━ [713 success] probe resource lustre:mgt 2024 Sep 22 19:06:27 ┣━━ [715 success] probe resource mariadb:DB 2024 Sep 22 19:06:25 ┣━━ [717 success] probe resource nfs:apps 2024 Sep 22 19:06:25 ┣━━ [719 success] probe resource nfs:ql-common 2024 Sep 22 19:06:25 ┣━━ [721 success] probe resource systemd:slapd 2024 Sep 22 19:06:25 ┣━━ [723 success] probe resource ip:Boot 2024 Sep 22 19:06:25 ┣━━ [725 success] probe resource ip:Extern 2024 Sep 22 19:06:25 ┣━━ [727 success] probe resource systemd:ql-mcastd 2024 Sep 22 19:06:27 ┣━━ [729 success] probe resource systemd:qluman-server 2024 Sep 22 19:06:27 ┣━━ [731 success] probe resource systemd:slurmdbd 2024 Sep 22 19:06:27 ┣┳━ [733 unconfirmed] Event restart resource 'systemd:qluman-dhcpscanner' 2024 Sep 22 19:06:27 ┃┗━━ [735 unconfirmed] stop resource systemd:qluman-dhcpscanner 2024 Sep 22 19:06:27 ┣━━ [737 success] probe resource systemd:slurmctld 2024 Sep 22 19:06:27 ┗━━ [739 success] probe resource systemd:qluman-slurmd
Pending actions are in the unconfirmed state as can be seen above for the restart event and stop action. To continue executing the action must be confirmed by listing the actions ID as argument to --confirm. Children of actions are confirmed when their parent is confirmed. So in the above example action ID 709, 733 or 735 can be confirmed. The alias all can also be used to confirm all unconfirmed actions. Say we confirm action ID 733 then the action status will change to this:
Actions: 2024 Sep 22 19:10:30 ┗┳━ [709 waiting] Repair for Resource Group 'core' 2024 Sep 22 19:06:25 ┣━━ [711 success] probe resource zpool:core 2024 Sep 22 19:06:25 ┣━━ [713 success] probe resource lustre:mgt 2024 Sep 22 19:06:27 ┣━━ [715 success] probe resource mariadb:DB 2024 Sep 22 19:06:25 ┣━━ [717 success] probe resource nfs:apps 2024 Sep 22 19:06:25 ┣━━ [719 success] probe resource nfs:ql-common 2024 Sep 22 19:06:25 ┣━━ [721 success] probe resource systemd:slapd 2024 Sep 22 19:06:25 ┣━━ [723 success] probe resource ip:Boot 2024 Sep 22 19:06:25 ┣━━ [725 success] probe resource ip:Extern 2024 Sep 22 19:06:25 ┣━━ [727 success] probe resource systemd:ql-mcastd 2024 Sep 22 19:06:27 ┣━━ [729 success] probe resource systemd:qluman-server 2024 Sep 22 19:06:27 ┣━━ [731 success] probe resource systemd:slurmdbd 2024 Sep 22 19:10:30 ┣┳━ [733 success] Event restart resource 'systemd:qluman-dhcpscanner' 2024 Sep 22 19:10:11 ┃┗━━ [735 success] stop resource systemd:qluman-dhcpscanner 2024 Sep 22 19:06:27 ┣━━ [737 success] probe resource systemd:slurmctld 2024 Sep 22 19:06:27 ┣━━ [739 success] probe resource systemd:qluman-slurmd 2024 Sep 22 19:10:11 ┗┳━ [741 unconfirmed] Event start resource 'systemd:qluman-dhcpscanner' 2024 Sep 22 19:10:11 ┗━━ [743 unconfirmed] start resource systemd:qluman-dhcpscanner
Both action 733 and 735 got confirmed and then executed successfully. This then resulted in the follow up actions to start qluman-dhcpscanner. These must be confirmed again to actually start the resource again.
Confirming an action also confirms future children of an action. So in the above if action ID 709 had been confirmed instead of ID 733 then the resource start for qluman-dhcpscanner would have been implicitly confirmed and executed automatically.
Besides --confirm actions can also be aborted by using --reject. This marks the action and all it’s children as failed. Which also means their parent actions will fail. The use case for this is when one disagrees with the suggested actions for fixing a resource or when an action was initiated by accident.
|
When rejecting a repair action it should be noted that the monitoring will notice a failed resource and just re-create the same repair action over and over if nothing else is done. The resource must be fixed by other means or through manual actions before rejecting a repair action becomes useful. |
5.1.5. Automation presets
At the top of the status output the automation settings and available automation presets are listed:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = [], general = [], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic
The above shows the default settings the router enters when freshly started. This matches the Maintenance preset that is created per default. For each of the 3 groups of automation settings (Core Resources, General Resources and Manual Actions) the actions that are immediately executed without extra confirmation are listed, in this case only manual start actions.
Individual settings can only be changed through qluman-qt but presets can be selected from qluman-ha-cli using the --preset command:
0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --preset Automatic 0 root@ql-head-ha-dev-1 ~ # qluman-ha-cli --status Automation: core = ['restart', 'migrate', 'koton'], general = ['restart', 'migrate', 'koton'], manual = ['start'] Mail Alerts: True Presets: Maintenance, Automatic
After setting a preset the new automation settings are shown in the HA status. In this example the default Automatic preset allowing the automatic free hand while manual actions are still subject to confirmation.
5.2. qluman-qt
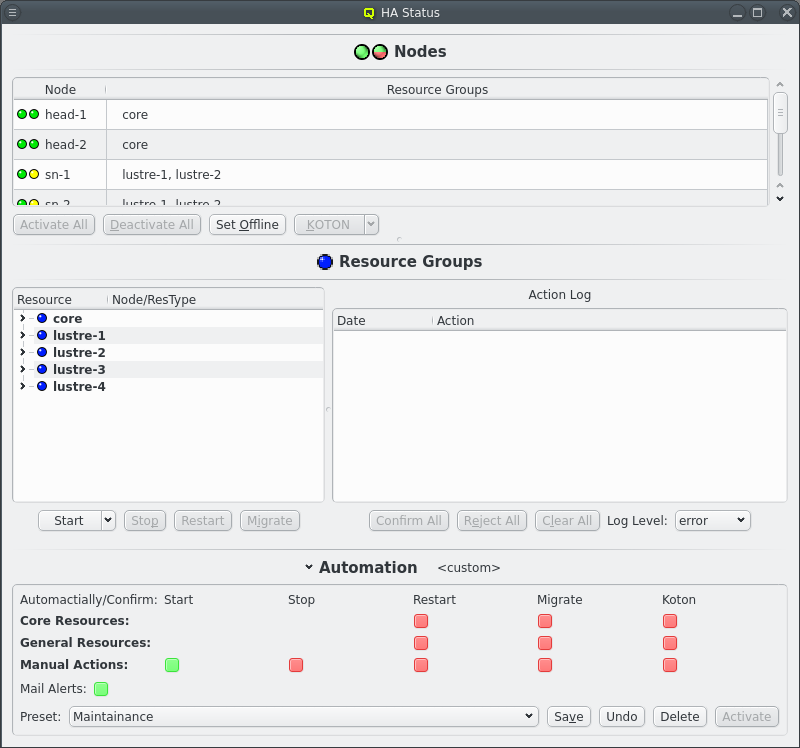
The HAStatus Window can be opened from the [HAStatus] or by clicking the HA Status button at the bottom of the main window. The window is split into 3 sections: Nodes, Resource Groups and Automation. The last of those starts up collapsed as it’s only interesting when changing the automation mode or when the name of the current automation preset isn’t enough information.
5.2.1. Quickstart
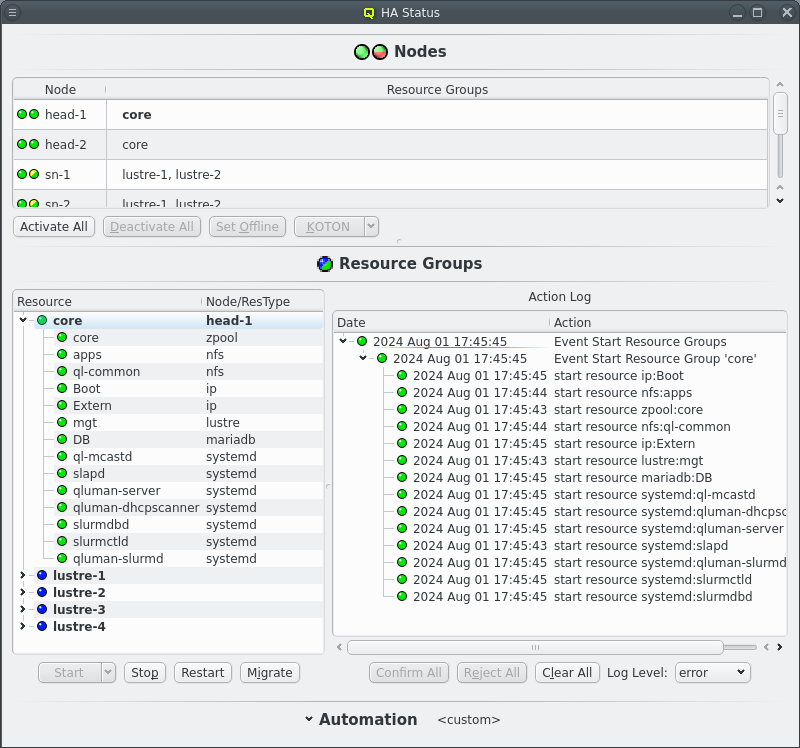
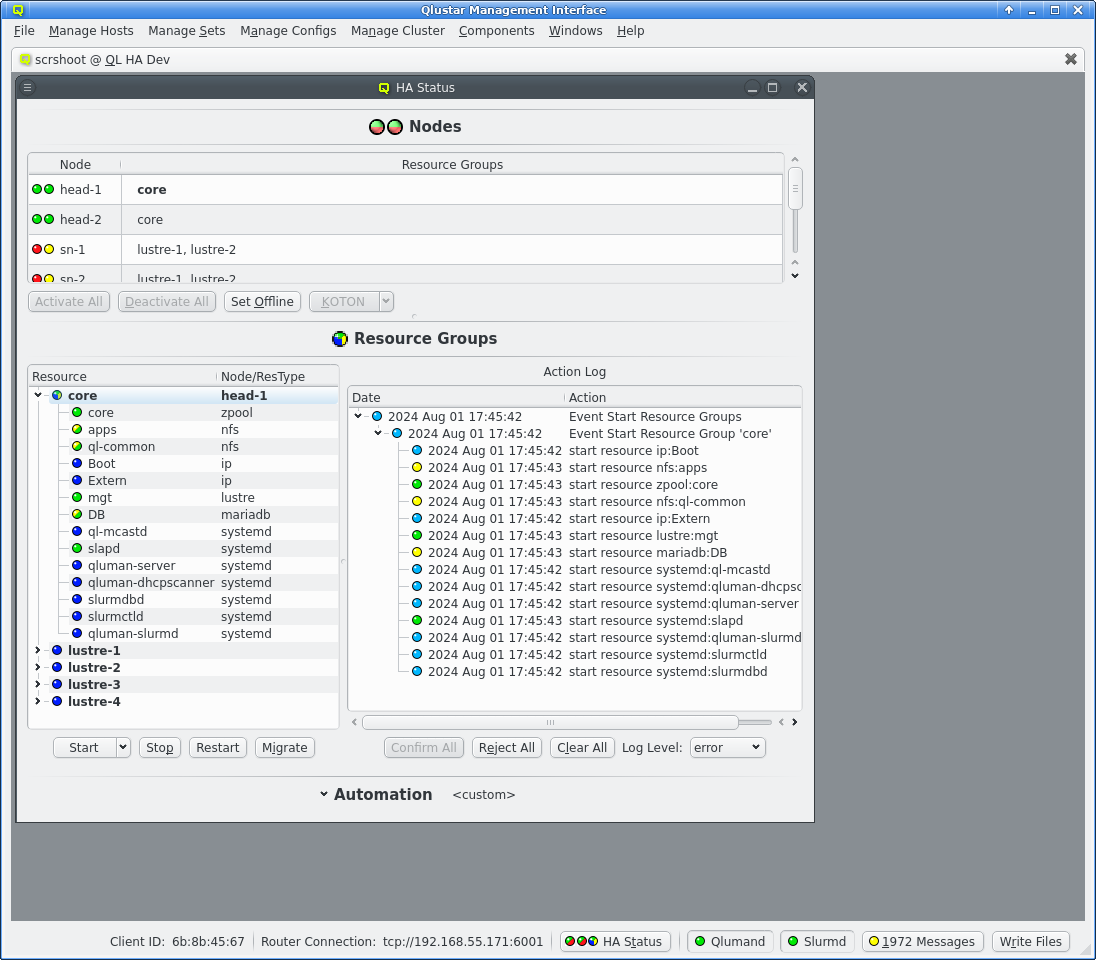
After a cold start of the cluster and the routers have been started the HA Status should show both head-nodes with 2 green LEDs and other nodes with a red/yellow LED combination. See the Nodes chapter below for details what those mean. All Resources Groups and Resources should have blue LEDs showing them as offline.
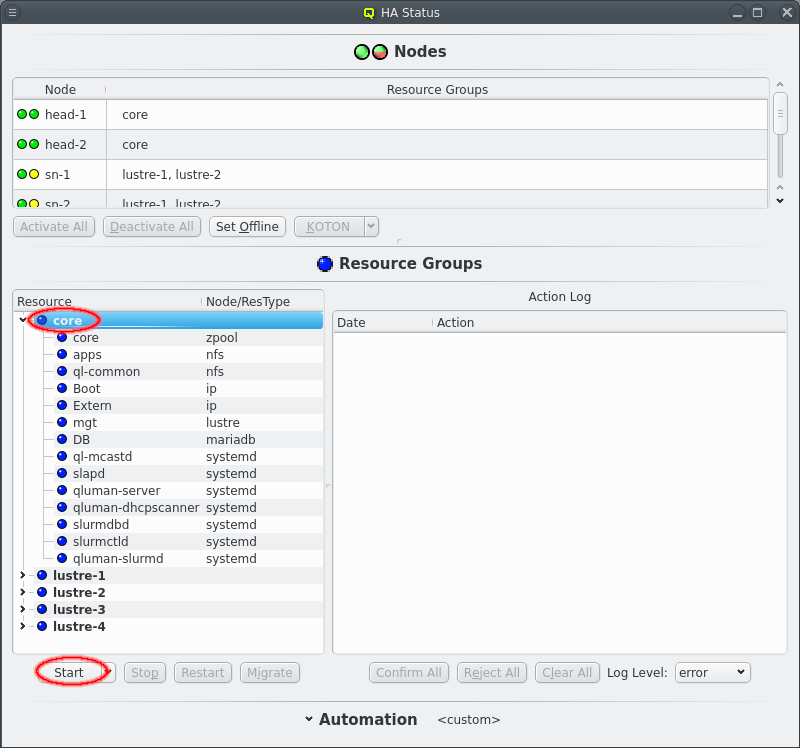
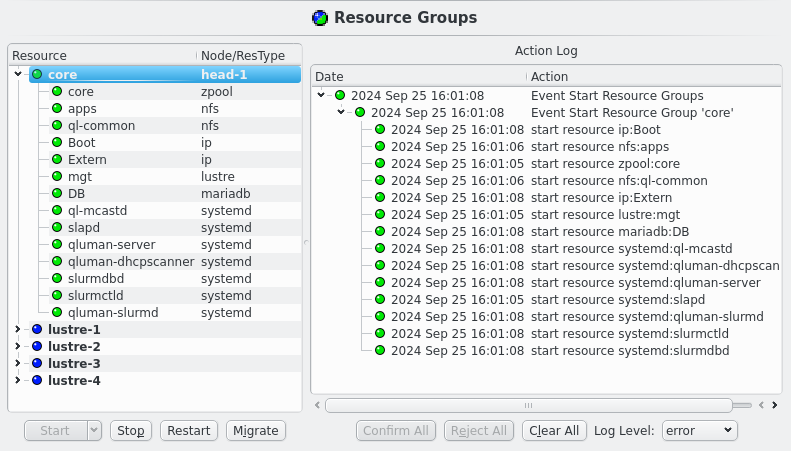
To start the cluster the core Resource Group need to be started first. Select the core Resource Group and then click the Start button. This should then show a new Action for starting Resource Groups in the =Action Log= at the right of the Resource Groups section. Since the default automation settings have start actions on automatic the resources will be started without further user intervention as can be seen by the chaning LEDs for both the Resources and the Actions. Eventually the Resource Group and the main Event for the start action should turn green signaling that all resources are online.
|
Expand the core Resource Group to see details for the Resources of the core Resource Group. Click the Clear All button to remove completed actrions from the Action Log display. |
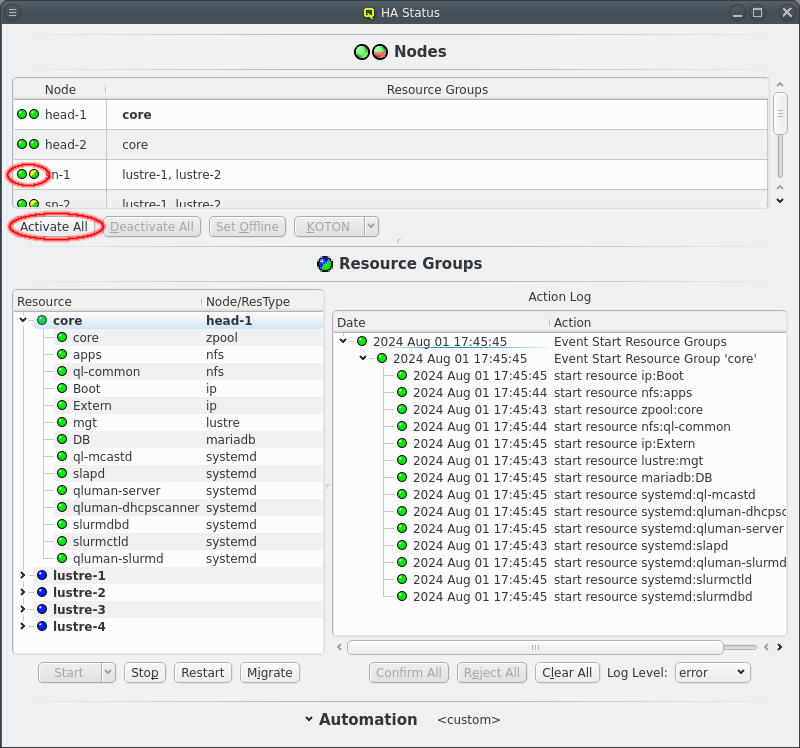
Once the core Resources are online the other nodes in the cluster can boot. At this point the KOTON status of nodes should turn green and once a HA node has booted it’s status should turn green/yellow signaling it’s readyness. Again since the startup is fickle HA nodes do not automatiocally become active. Click the Activate All button to activate all ready nodes or select nodes and activate them individually.
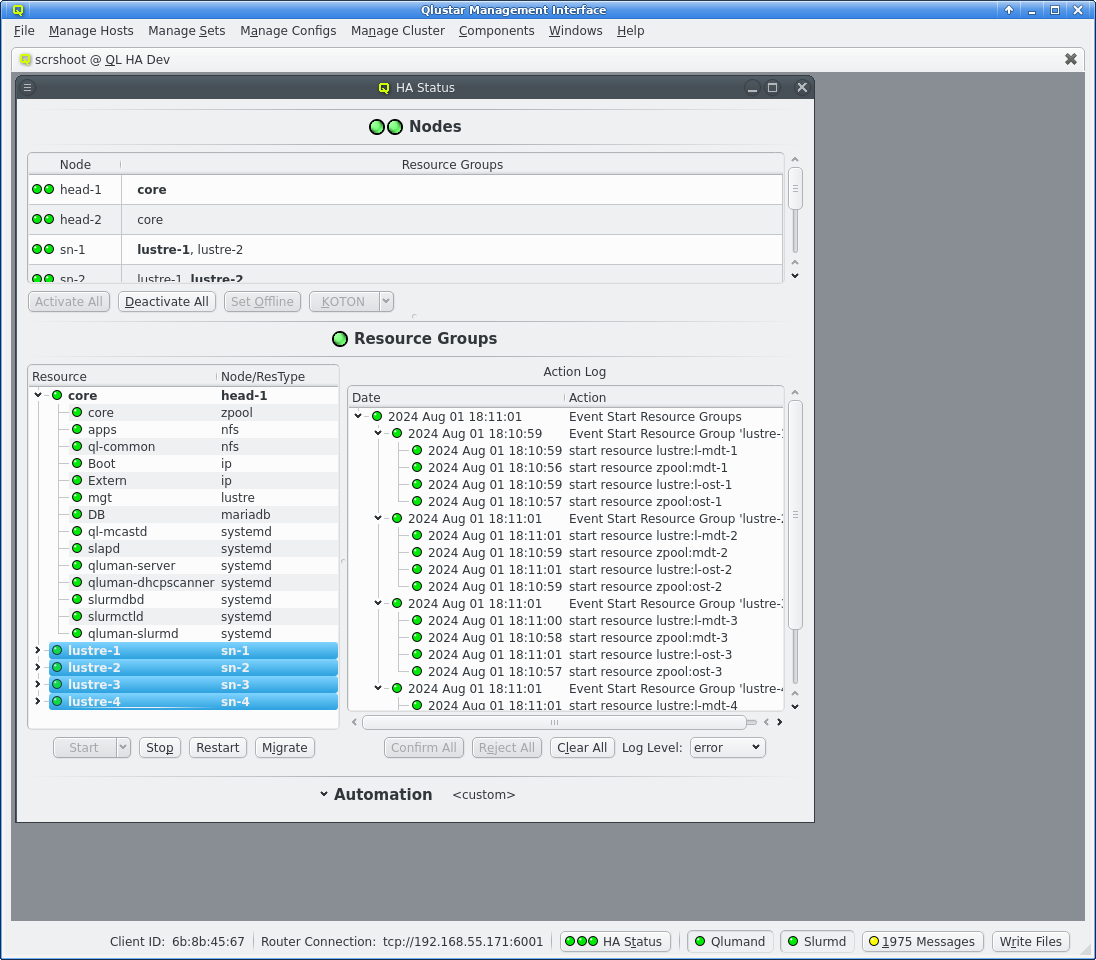
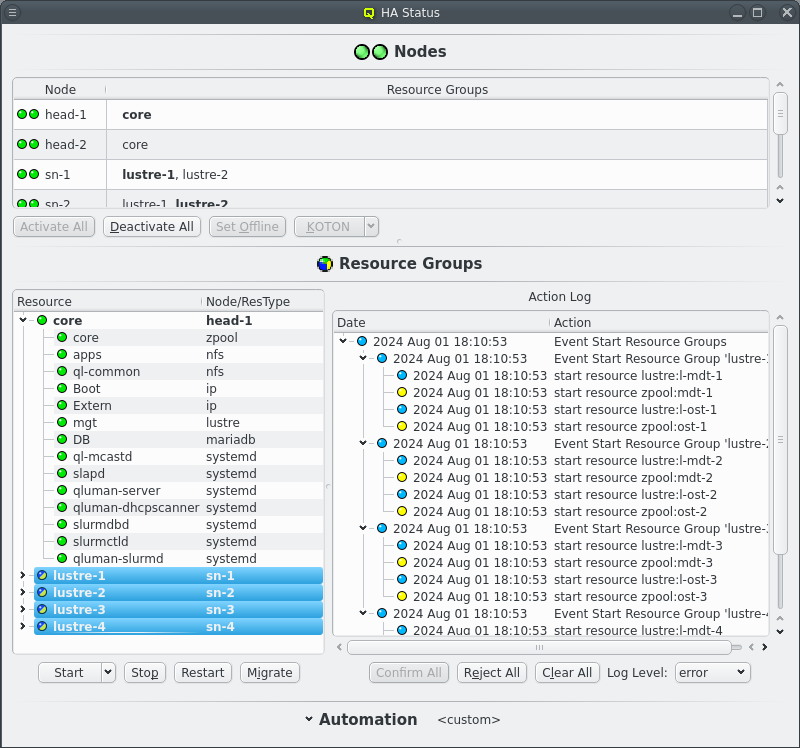
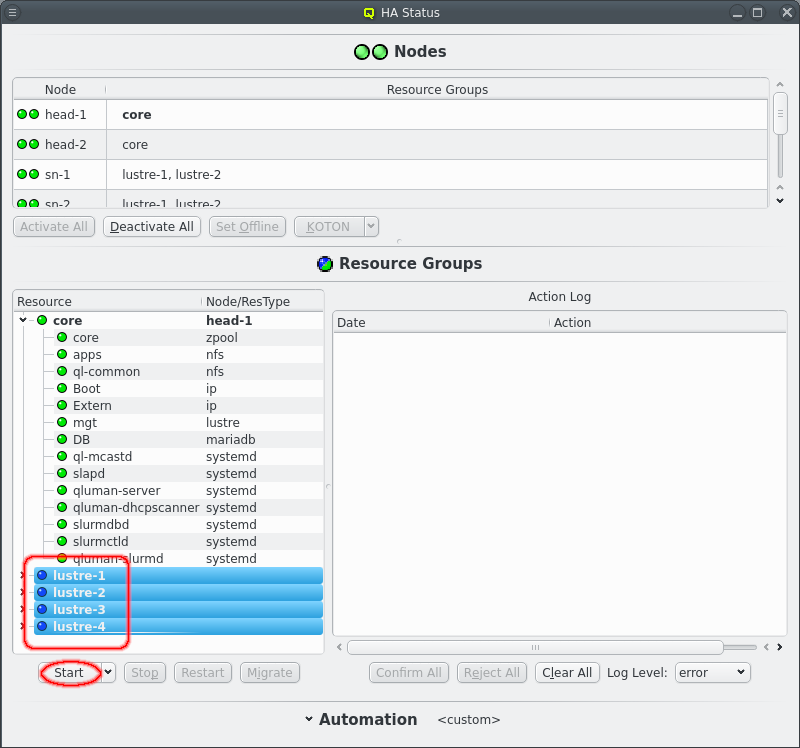
Once the remaining HA Nodes are activated the remaining HA Resource Groups can be started. Select the resource groups and click the Start button. Again an Event will appear in the Action log, this time with multiple sub events, one per selected Resource Group. Again the status LED will change as actions are executed and Resources become online.
Hopefully after a short time all LEDs are green and the cluster is ready for use.
5.2.2. HAStatus: Nodes
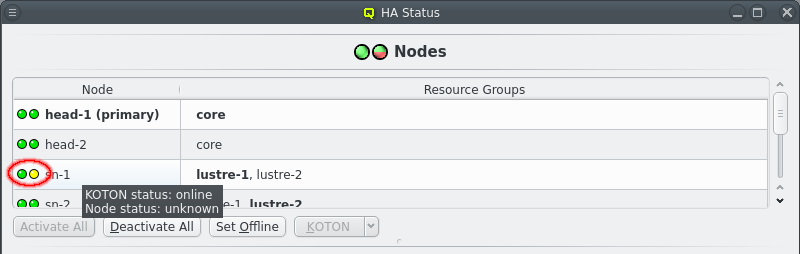
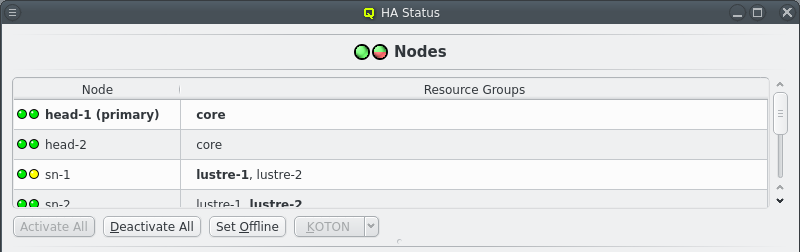
The Nodes section in the HAStatus Window shows the status of all HA Nodes in the cluster, the Resource Groups assigned to each node, marked in bold if the Resource Group is running on the node. The primary head-node, determined by having the core Resource Group running on it, is marked in bold and with the string "(primary)".
Each node has 2 status LEDs. Hovering over a node will show a tool tip listing the status for each LED. The left LED indicates the availability of power management via ipmi. The nodes power status is periodically checked to ensure the ipmi connection is working. This ensures KOTON can be performed when necessary. The right LED indicates the status of the node itself. A green LED indicates all is well. A yellow LED indicates that the status is unknown and the node is unreachable. A red LED indicates an error. A a dark blue LED indicates an offline node.
Unlike yellow or red an offline node is in a well defined state where it is known that none of the Resource Groups are currently running on that node. A node is marked offline after a successful KOTON of the node. Power cycling ensures that the node has stopped running any of the Resource Groups. The only other way to get a node into offline state is to manually set it offline. Select a node and click the Set Offline button. This is a promise to Qluman that none of the Resource Groups are running on that node for cases where the node should not or can not be KOTONed.
Last a yellow/green LED indicates a node that is ready but has not been set active for HA operations. When a node it first booted or reboots after being KOTONed the node is not automatically used for HA. A node is KOTONed when a Resource can not be stopped, usually due to kernel or hardware failures and a power cycle is the only way to ensure the Resource is released. As such the admin should investigate the node to make sure the error has been resolved before returning the node to active status. The active status of all nodes can be changed by clicking the Activate All or Deactivate All buttons. The same buttons can also be used to change individual nodes by first selecting the respective nodes.
When a node is selected the KOTON action can also be triggered manually. This comes in two flavours, selectable from the drop down menu on the button. The default when simply clicking the button is to first migrate resource groups away from the selected node before triggering a power cycle via IPMI. This is the preferred method if the node is still somewhat functional as it allows a cleaner transition of resources from one node to the other. But it can take a long time when resources can not be stopped due to kernel or hardware errors. The other option is to "Power off now", which does as it says and immediately trigger the IPMI power cycling without first trying to stop resources. Post KOTON the Resource Groups that were running on the selected node are still restarted on the alternate node for each Resource Group if possible.
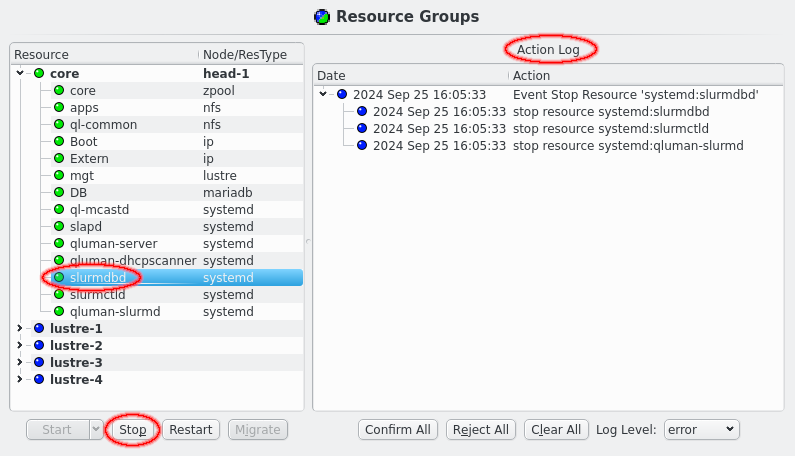
5.2.3. HAStatus: Resource Groups
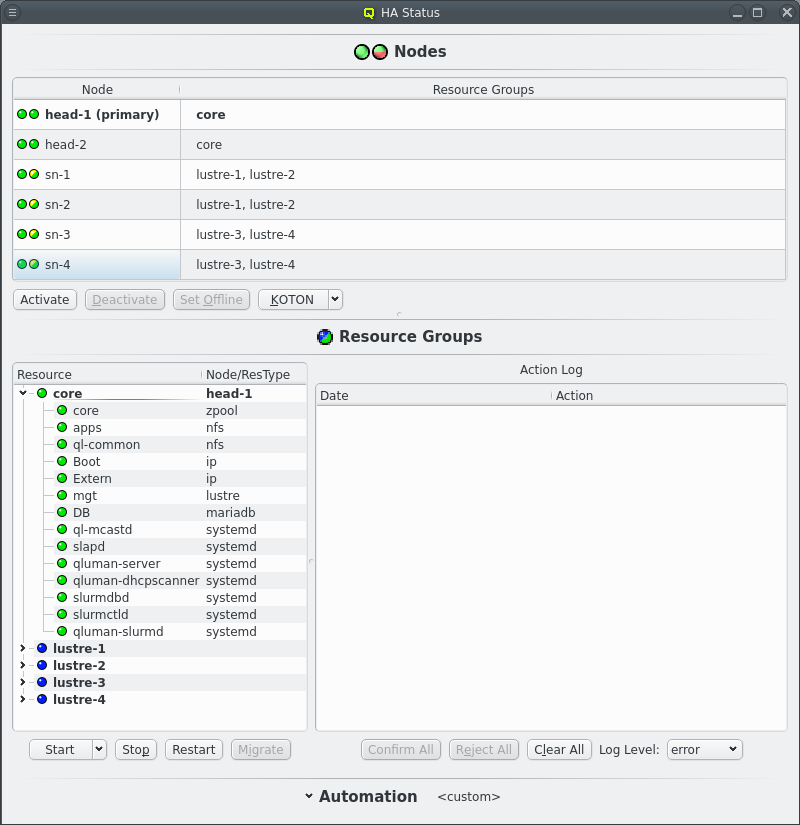
The Resource Groups section is split in two parts, the actual resources and resource groups on the left and the Action log on the right. The resources and resource groups are arranged as a tree with the resource groups at the top level. In front of each resource is an LED showing the current status of the resource. In front of resource groups is a combined LED showing the merged status of all resources of that group. In the second column the resource type is listed for each resource while for resource groups the current node of the resource group, if any, is shown in bold.
A yellow LED denotes a resource in unknown state, where the HA system hasn’t yet determined the true state of the resource. A dark blue denotes an offline resource while green denotes online and a resource with error will be marked in red. Resources with pending actions are marked with a split LED. One half is yellow denoting that the resource is in some intermediate state while the other half is colored for the targeted state, dark blue if the resource is to be offline and green if the resource is to be online at the end of the action.
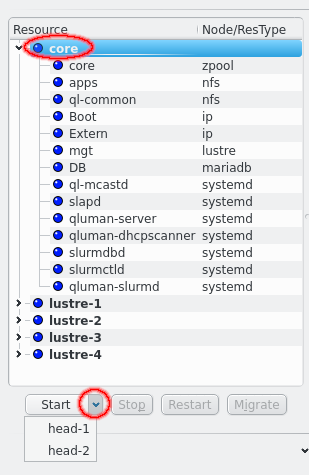
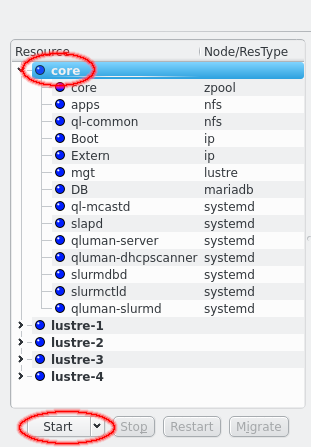
At the bottom are 4 buttons for the actions that can be initiated for resources and resource groups: Start, Stop, Restart and Migrate. Depending on the selected resources or resource groups different buttons will be enabled. A resource can only be started when it is offline and only stopped when it isn’t offline. Offline resources can’t be restarted and only resource groups with running resources can be migrated. When nothing is selected the available actions will apply to all resources. In case of the Start button the button can be simply clicked to start a resources on the current node of the resource group or the preferred node if the resource group has no current node. Alternatively the down arrow can be clicked to open a drop-down menu to select the specific node a resource or resource group should be started on.
Clicking an action will add the selected action to the Action Log on the right. Depending on the automation settings for manual actions, see next chapter for details, the action will wait for confirmation or immediately execute.
|
The system will also create actions when monitoring detect a problem with a resource. For those actions the Core Resources or General Resources automation settings apply. Apart from that they behave like manual actions. |
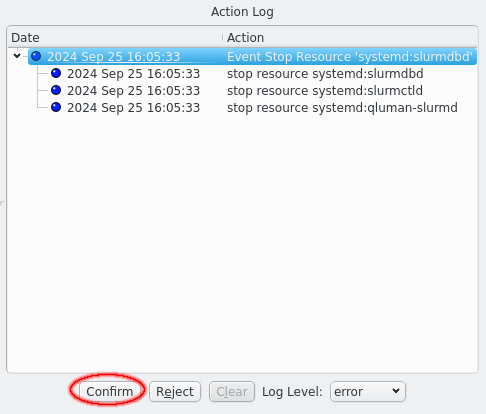
Each action in the Action Log box has a timestamp showing the time of the last activity for that action as well as a status LED showing the current status. Actions that are awaiting confirmation have a dark blue LED which turns light blue when the action is confirmed but waiting on other actions to complete first. A yellow LED is shown when an action is currently running, which turns green on success and red on failure.
To confirm an action for execution select the desired action and click the Confirm button. Confirming an action will also confirm all present and future children on an action. If an action should not be executed click the Reject button instead. Rejecting an action marks the action as failed, which means any parent action will also fail. This does not affect siblings though. When no action is selected the Confirm All and Reject All buttons will affect all actions.
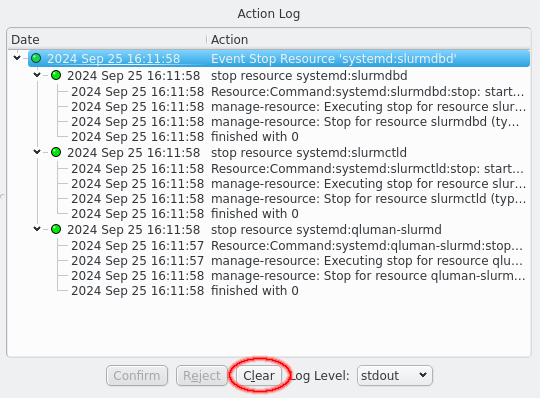
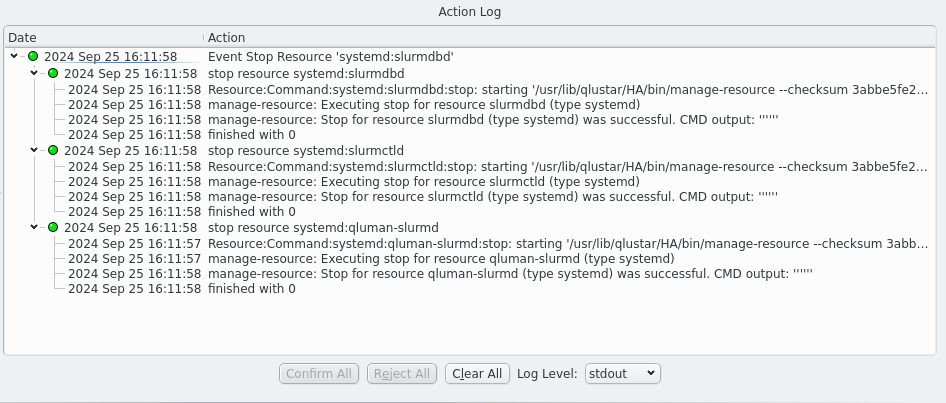
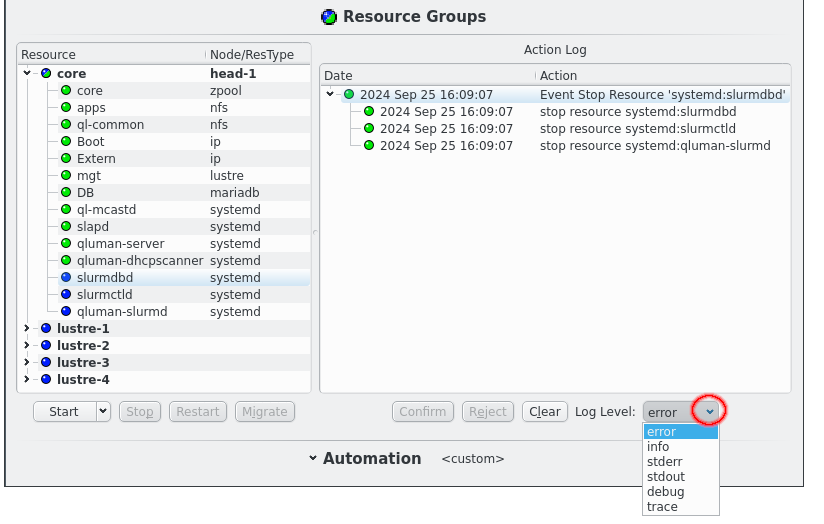
Once an action has been confirmed it will start executing commands. Details of the execution can be seen by increasing the Log Level using the drop-down menu. The highest level, error, only shows critical error messages. Next lower is the info level, which also shows commands being started and their return code. The stderr and stdout levels include the output of commands in the display and can show important details of why a command failed. Last the debug and trace levels are there for debugging the code in case it misbehaves and will be useless to most users. Please ignore. Once a level has been selected the Action Log will update to show all log messages of the selected or higher level. This works retroactively, it is not necessary to select a log level before an action is executed to see more details.
Once an action has finished it can be removed from the display by clicking the Clear button. If no action is selected the Clear All button clears all finished actions. Actions that have not finished are not affected. In case of a failed action this will also remove the action from the server. Successfull actions are automatically removed from the server on completion to preserve memory but remains visible in the Action log as long as it remains open. Closing and opening the HA Status window will not show actions already removed from the server.
5.2.4. HAStatus: Automation Settings
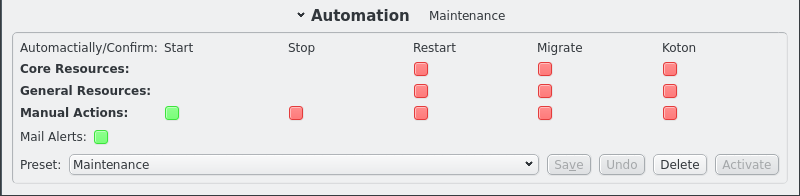
The point of an HA setup is to ensure availability when things go wrong. So far all actions have been initiated manually and generally required confirmation by the user. That defeats the purpose of an HA setup and is more like a cold standby. But that is because the automation settings start in maintainance mode when a cluster is started cold. It is important to realize that in the QHAS design there is no difference in how the system behaves in different automation modes. What automation means in a QHAS context is to automate the confirmation step in the logic. That and only that.
QHAS will always create actions to restart failed resources, to migrate resource groups and to KOTON nodes beyond recovery regardless of the automation settings. The automation settings will let you choose which of those proposed actions will require manual confirmation and which will be executed automatically.
Automation settings for actions are split into 3 groups: Core Resources, General Resource and Manual Actions.
Manual Actions covers any action created by the user via the qluman-qt GUI. It’s a protection against accidentally pressing the wrong button or having the wrong Resource or Resource Group selected. Per default all but the start action requires a confirmation of the action in the action log. If having to confirm every action becomes tiresome after a while this where to change that.
The other two groups only relate to repair actions done when monitoring fails to confirm a resource is working. As such it has no options for start and stop as a repair will never initiate those actions except as part of a larger operation. The Core Resources group governs any repair for the core Resource Group while all other Resource Groups are governed by the General Resources settings. The core Resource Group is essential to the working of the cluster. Without it nodes can not boot and won’t get their configuration at boot. It therefore uses separate settings from other Resource Groups.
Another important automation setting is Mail Alerts. When activated e-mails are send whenever an repair action is proposed that requires confirmation or whenever an action finishes. For the confirmation email the proposed actions are listed. For a finished email the result of the action, success or failure, is included in the subject as well all the steps taken. The main mail only includes the top level output for all actions while attachments are included listing all the output and even debug information of the internal workings. The contents match what is available in the Action Log when qluman-qt is running.
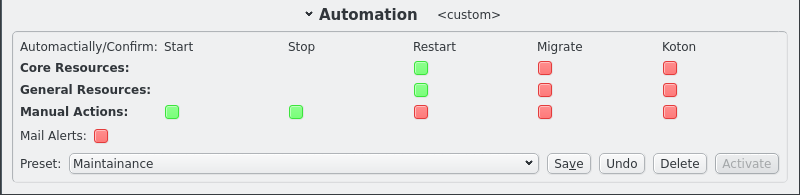
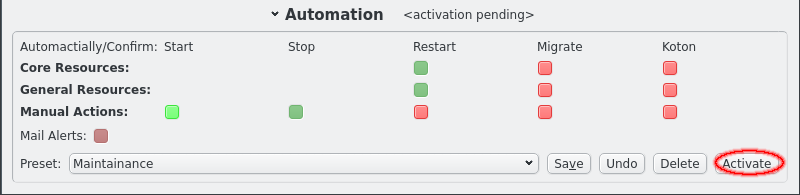
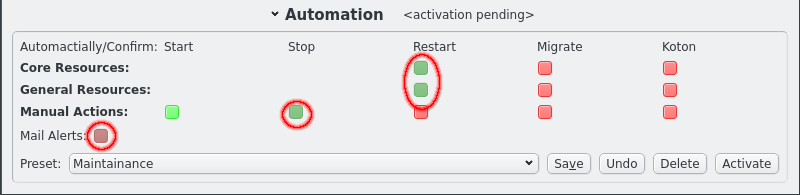
Automation settings can be changed individually by clicking the respective LED buttons. The collor will change to reflect the indended setting. But the the LEDs will be greyed out because the setting does not immediately take effect. One reason for this is that it allows editing presets as will be shown below. To make the settings take effect the Activate button must be clicked. Note that the title for the Automation section changes when changes are pending or when settings are active that do not reflect a saved preset.
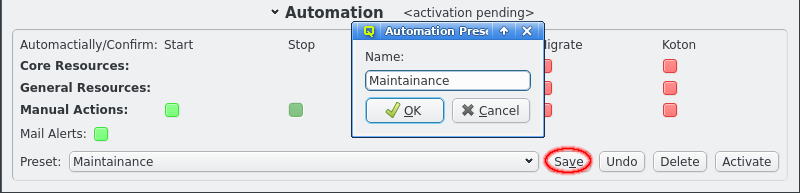
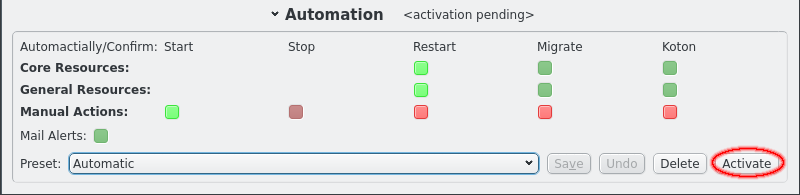
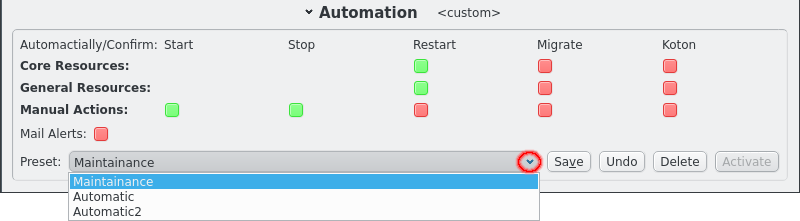
Automation settings can also be set to a preset selected from the list of saved presets. After selecting a preset click the Activate to make the settings take effect.
Presets can be edited or new presets can be created simply by adjusting the LED buttons for the automation settings and finally clicking the Save button. Saving the presets under the current name will overwrite the preset and changing the name will create a new preset. The automation settings can also be restored to the saved preset by clicking the undo button. Finally presets can be removed by clikcing the Delete button.
|
Automation Setting can also be changed via qluman-ha-cli --preset <name>. The command line interface only allows selecting one of the saved presets. The list of available presets is included at the top of the qluman-ha-cli --status output right below the current automation settings. |
6. Internals
6.1. Files storing the internal state
The internal state of the QHAS is stored in several files in the filesystem. Some of them are permanent and persist across reboots while others last only till the next reboot.
The first file is the main configuration files for nodes, resource groups and resources. This is generated by qlumand and stored in /etc/qlustar/HA/resource.cf and reflects the desired configuration for the HA system. The qluman-router copies this to /run/qlustar/HA/resource.cf when the configuration is activated to reflect what configuration is actually running at the moment. The file is a direct reflection of the HA configuration done in qluman-qt.
The next file is /run/qlustar/HA/automation and stores the current automation settings for the router. Specifically which core, general and manual actions require manualy confirmation and which are confirmed automatically. It also says if alert mails are to be send or not. The automation settings can be seen at the top of qluman-ha-cli --status or in the HA Status window in qluman-qt. This file is only written when the automation settings are changed, otherwise default values matching the default Maintainance settings are used.
The third file is /run/qlustar/HA/status and contains the current status for each node and resource and if the resource should be running or not. This should always match the output of qluman-ha-cli --status, which is also more easy to read. Removing this file while restarting qluman-router resets everything to a clean state at the risk of not knowing a resource is already running. The router probes all resources on start though and will recover the status for any online resource. Only error states and desired state is lost. This file is updated every time the status of a resource changes.
6.2. Router startup and reconnect logic
On startup the qluman-router will read in the 3 state files mentioned above for the resource configuration, automation settings and resource status. Each file is checksummed and the timestamp of the file is read. This is used as starting off point for the router.
The router then tries to connect to it’s alternate head. Each time a connection is established the two router exchange the checksum and timestamp of the 3 status files to assert they are in sync. If differences are found in any of the 3 files the timestamp is used to figure out the newer file and the content of that file is send to the head-node with the older file and it’s status is updated. This solves the split brain problem and any status changes occuring while the connection between routers was missing is corrected. When both routers agree on the state of these 3 files they are said to be in sync. As a final step running or pending actions are pushed to the other head-node.
On start the routers also each check the resources that could be running locally to verrify the state of those resources remains the same as the status file. Specifically resources started while the router was offline (or because the status file was deleted) are detected. The primary head-node also probes resources on each netboot note when it becomes active or reconnects while being active for much the same reason.
6.3. Router actions
Everything the QHAS system does is encoded in actions. Actions that don’t do anything are called events and only group other actions together. This forms a tree structure with a parent event and child actions or events. They also form a directed graph where one action waits for another action to complete before running.
Each action also has a log that records progress of the action through its stages with timestamps. This can be seen using qluman-ha-cli --status --verbose or when increasing the log level for the Action Log in the HA Status window in qluman-qt. This is usually much more readable than looking at the router.log or router-ha.log as entries for each action can be seen seperately.
Note that actions are not part of the state saved on disk and are lost when both head-nodes are stopped. They are restored though when only one head-node is stopped and then restarted and will continue where they left off, if possible.
The loss of action is not an issue though as the QHAS system relies on the current and desired state of the resources to make decisions. So lost actions are simply recreated on restart in an attempt to bring the current resource status in sync with the desired state. Which is also why rejecting an action without other changes made has the same action simply reappear a while later.
7. Failure handling and recovery
7.1. QHAS handling of error scenarios
7.1.1. Failure while starting a resource
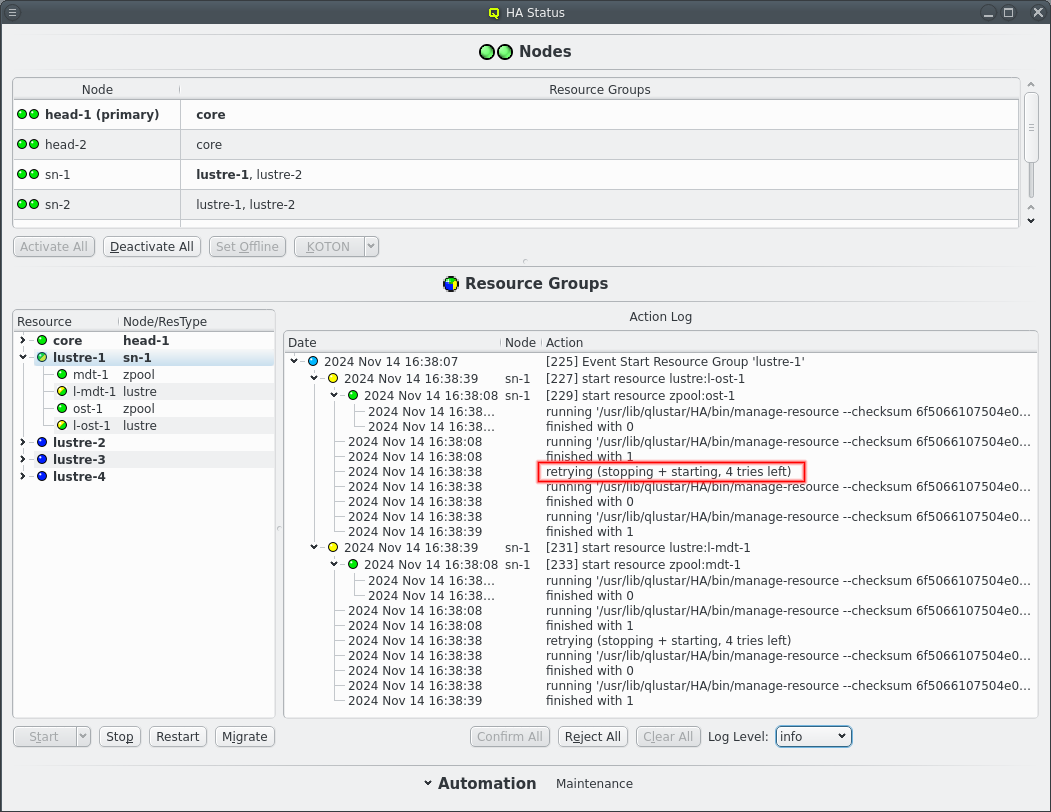
The start of a resource can fail on a node for whatever reason. The start of the resource is then retried up to 5 times for manual actions or up to the respawn limit for automatic actions, i.e. when a restart is triggered due to monitoring errors. Before each start retry the resource is stopped to clean up any remains from the previous try. The repeated attempts can be seen in the Action Log when the log level is raise to at least /info/.
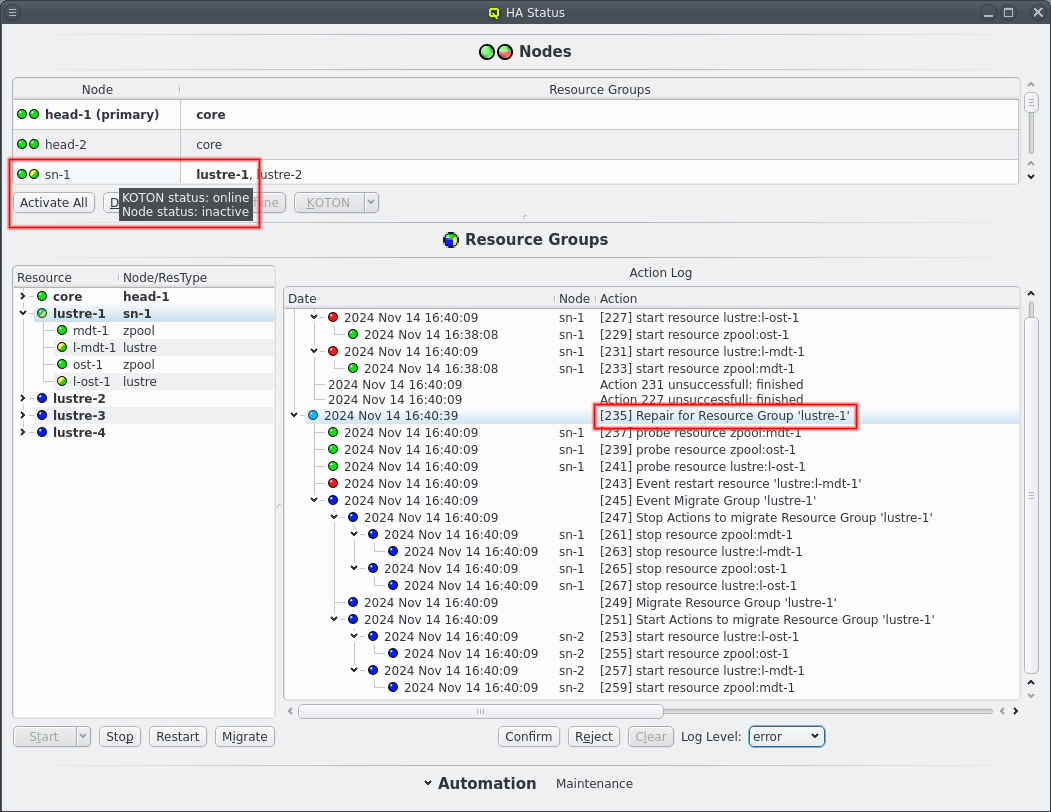
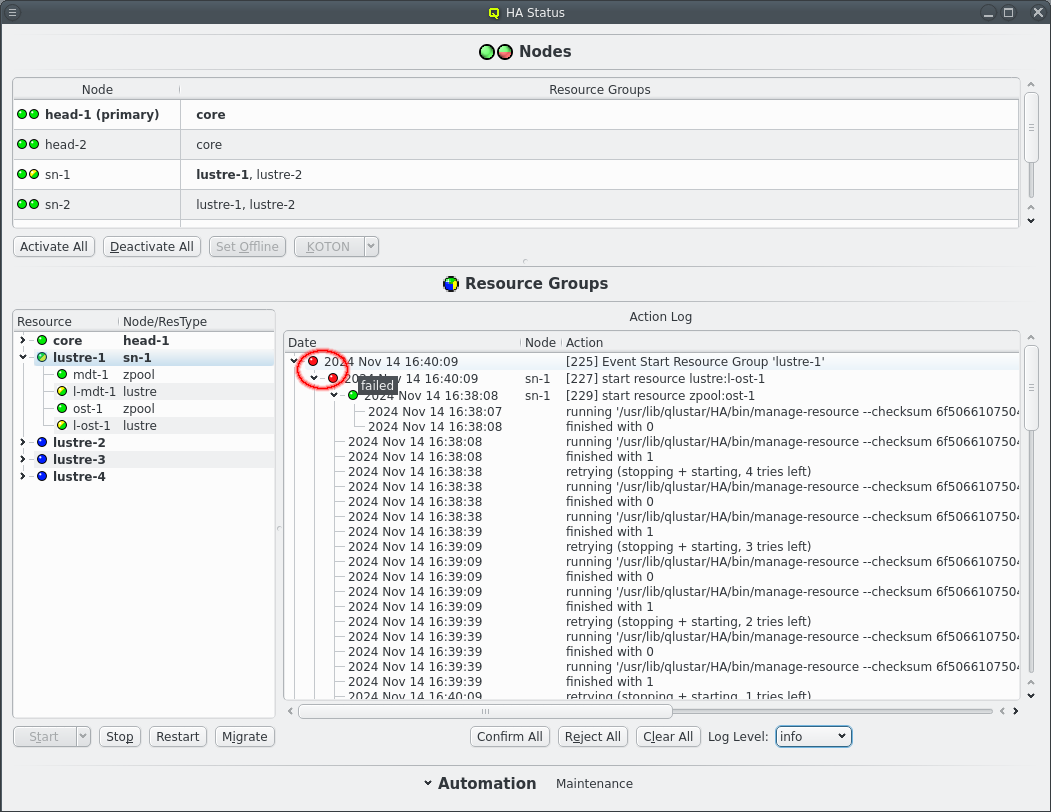
If the resource refuses to start too often the start attempt is marked as failed and a repair action is initiated, or an ongoing repair action is extended, to migrate the resource group to the alternate node. The node with start failures is also marked inactive to prevent resources from migrating to a probably damaged node. Resource groups other than the one with the failed resource are left running on the node though for as long as monitoring detects no errors.
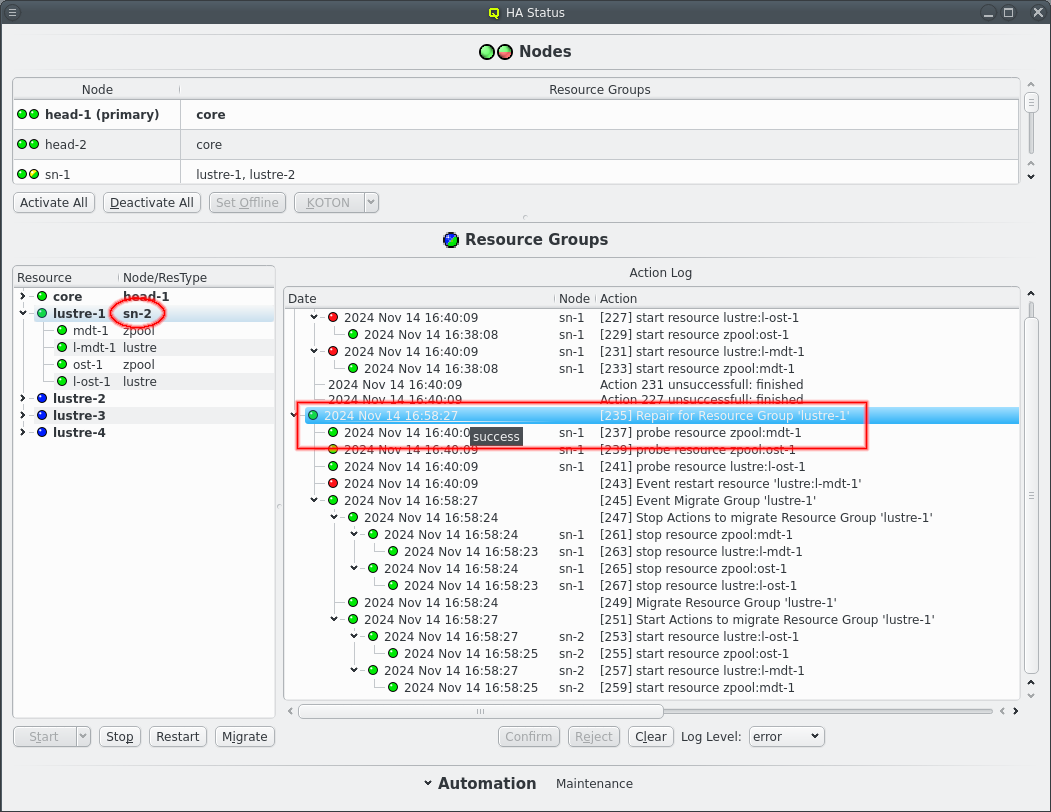
The final result of the repair action, assuming a successful repair, will be that the affected resource group now runs on the alternate node and the action is marked as success.
7.1.2. Failure while stopping a resource
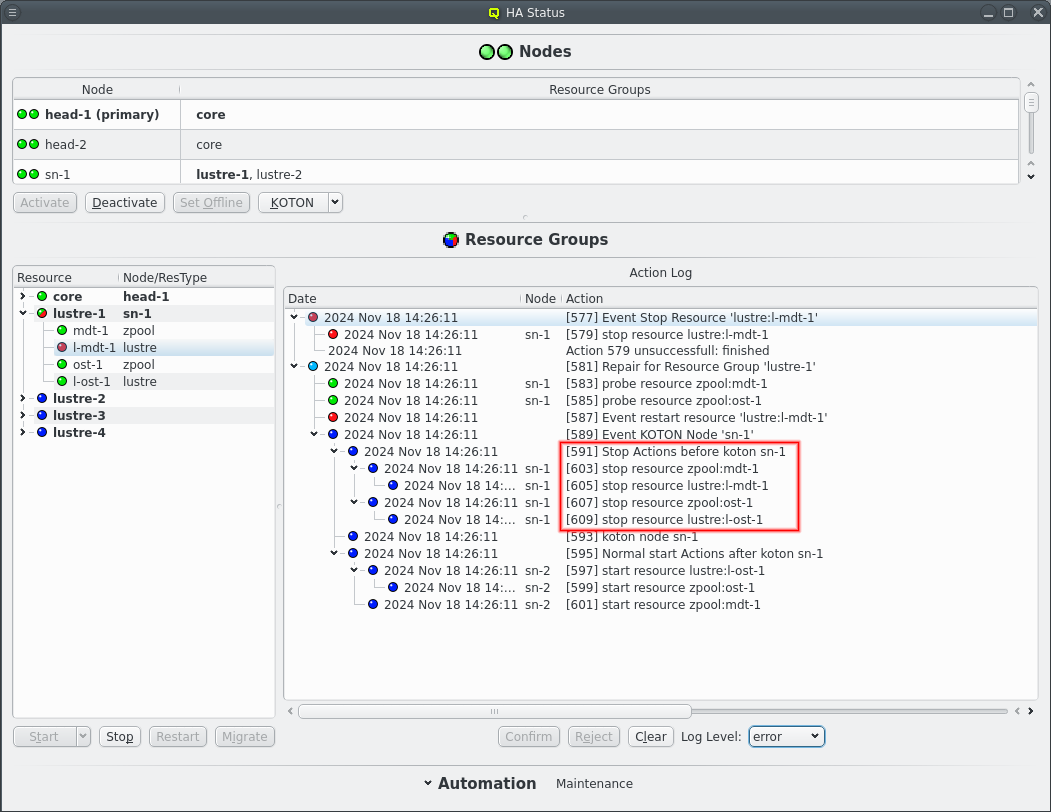
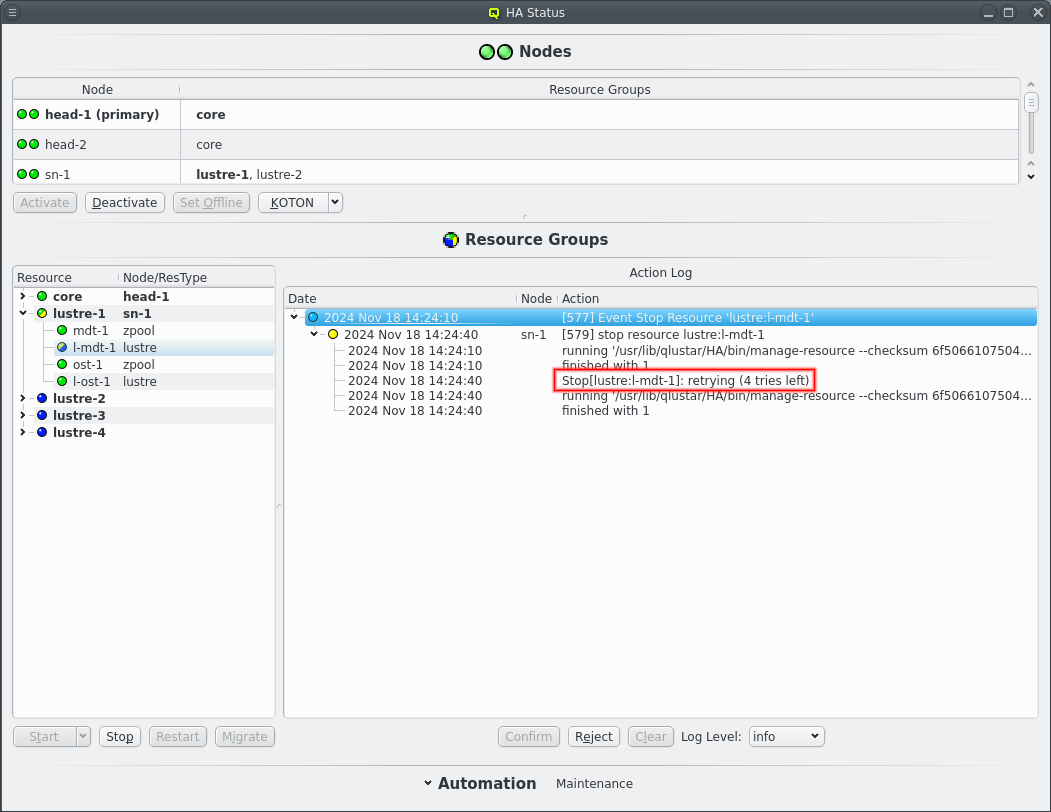
Similar to the start of a resource stopping a resource can also fail and just like start the stop action is atempted multiple times and can be seen in the Action Log when the log level is raise to at least /info/. A failure to stop is more serious than start though as then there is no way to completely shut down the resource so it can be safely started on the alternate node. The only choice left is to power cycle the problematic node via KOTON action.
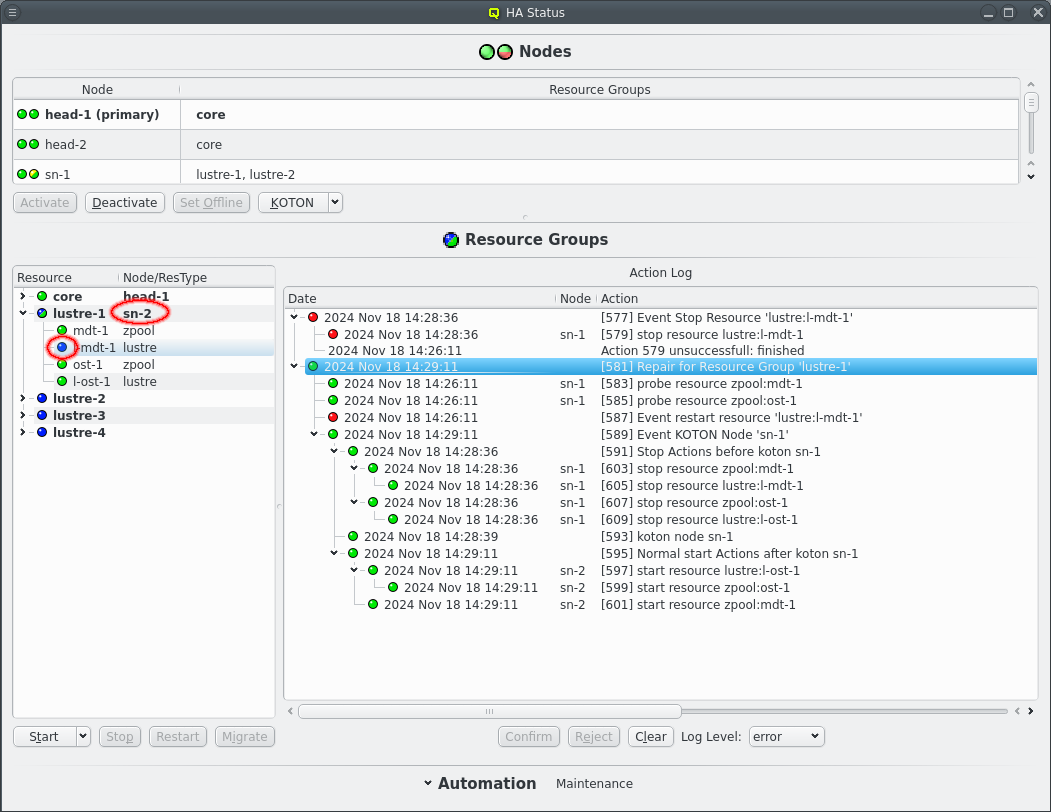
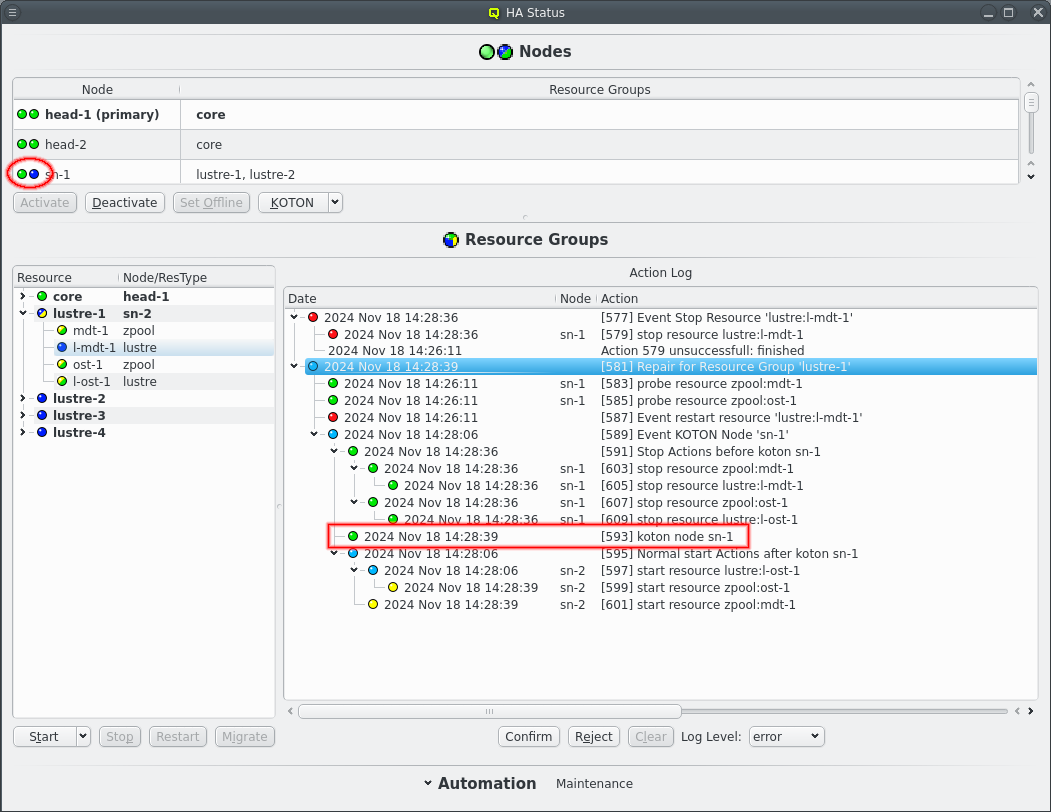
Before taking that step any other resources running on the same node are stopped, if possible, as a clean shutdown is preferable to simply turning of power. If the other resources also fail to stop this can cause a large delay if each stop action fails only with a timeout. This should be rare as in most cases the stop action either succeeds or returns quickly with an error.
Note that when the repair action has finished the resource group now runs on the alternate node and the resource that failed to stop is not running. This is because the stop failure occured on a manual stop, the user asked for the resource to be stopped so it remains offline after the repair. If the stop action had failed during a restart or repair action then the resource would have been brought back up on the other node as there was no intention of keeping the resource offline.
7.1.3. Monitoring of a resource detects an error
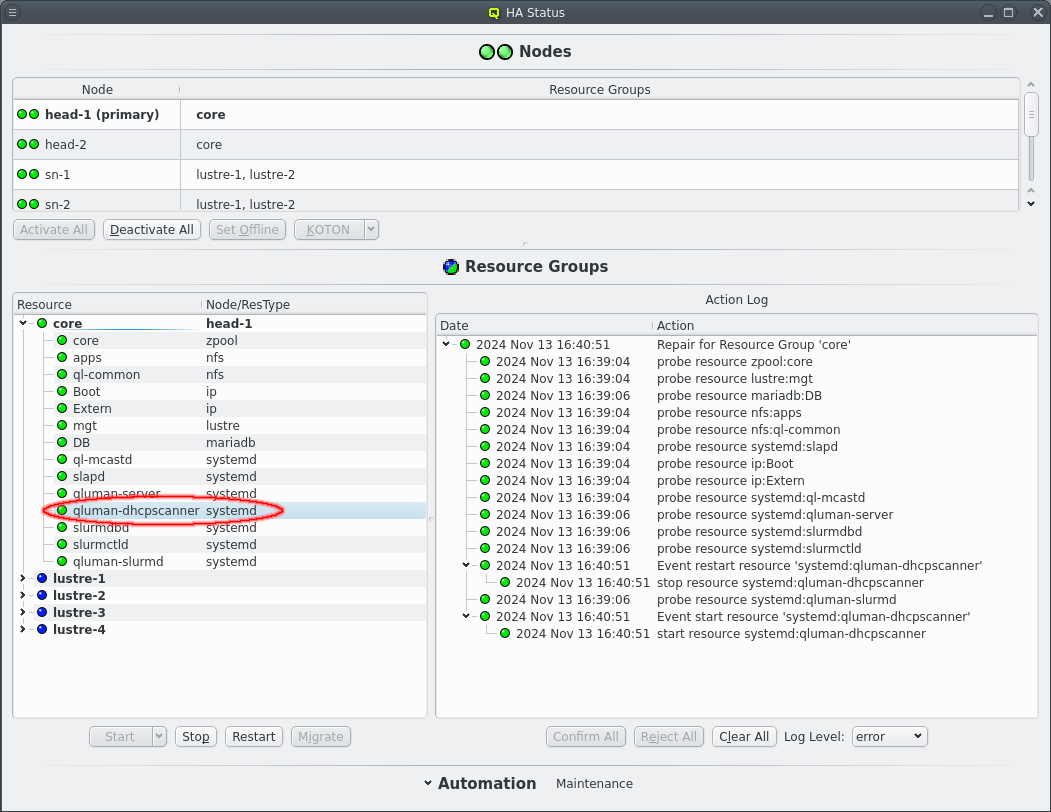
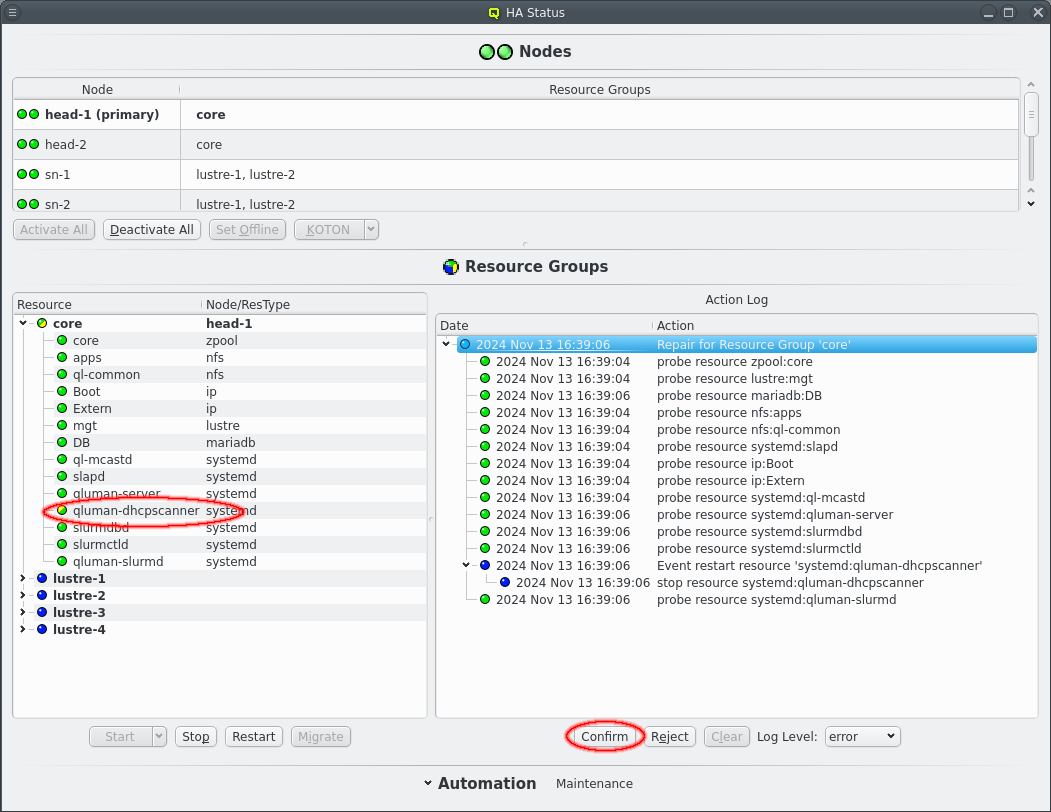
Each resource is periodically checked to assert it’s still functional. When the check reports an error or fails complete in a timely manner a repair action is created for the failed resource. In this case the monitoring has detected that the dhcp-scanner is no longer running. If the automation settings allow it the next steps run on their own. Otherwise, as shown here, the repair stops and waits for the admin to confirm the planned action.
The first step is to stop the resource. This is done to clean up any remnants of the resource that might still be running, to make sure the resource is completely offline and in a clean state. This will also honor the dependencies of resources, so resources requiring dhcp-scanner (none here) are stopped as well. After that the resource and dependencies are started again to restore the system to a functional state.
If there is no larger underlying problem the repair will finish with the resources online on the same node again.
7.1.4. Unresponsive HA node
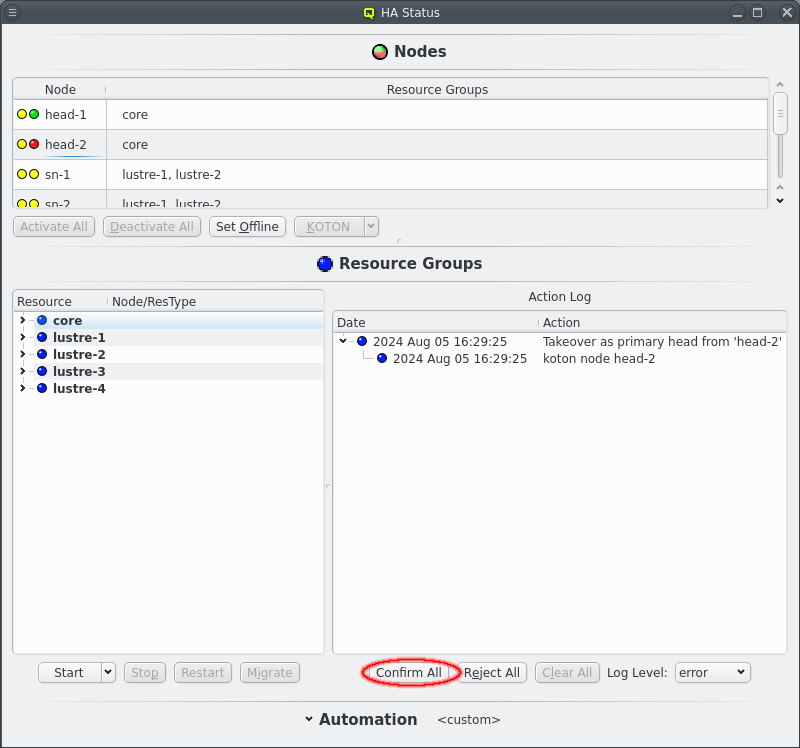
QHAS normally requires both head-nodes to be running before it allows starting the core resources. The reason for this is that resources must never be started on two hosts at the same time to prevent data corruption in filesystems or databases. So the requirement isn’t so much that both head-nodes are running but that the head-nodes knows no resources are running on the other head-node.
There are two ways to achieve this. The first is to tell one head-node that the other head-node is offline using
qluman-ha-cli --set-ofline head-2
This marks the head-2 node as offline, promising that no resources are running on that node. This should not be promised lightly but ZFS is configured in multihost mode as additional check to prevent mounting the zpool core resource on both heads at the same time. Starting core twice would just fail to start.
The other way is to wait for the timeout for connecting both heads to expire. The running head-node will then propose an action to take over as primary head-node from the other head-node and to KOTON said head-node. This action can be confirmed either via qluman-ha-cli or qluman-qt.
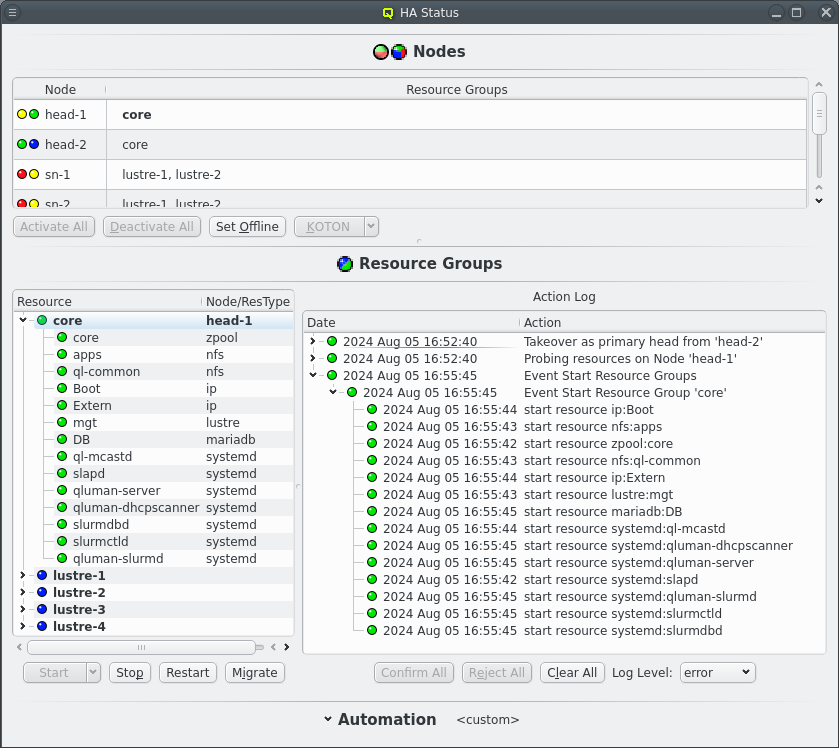
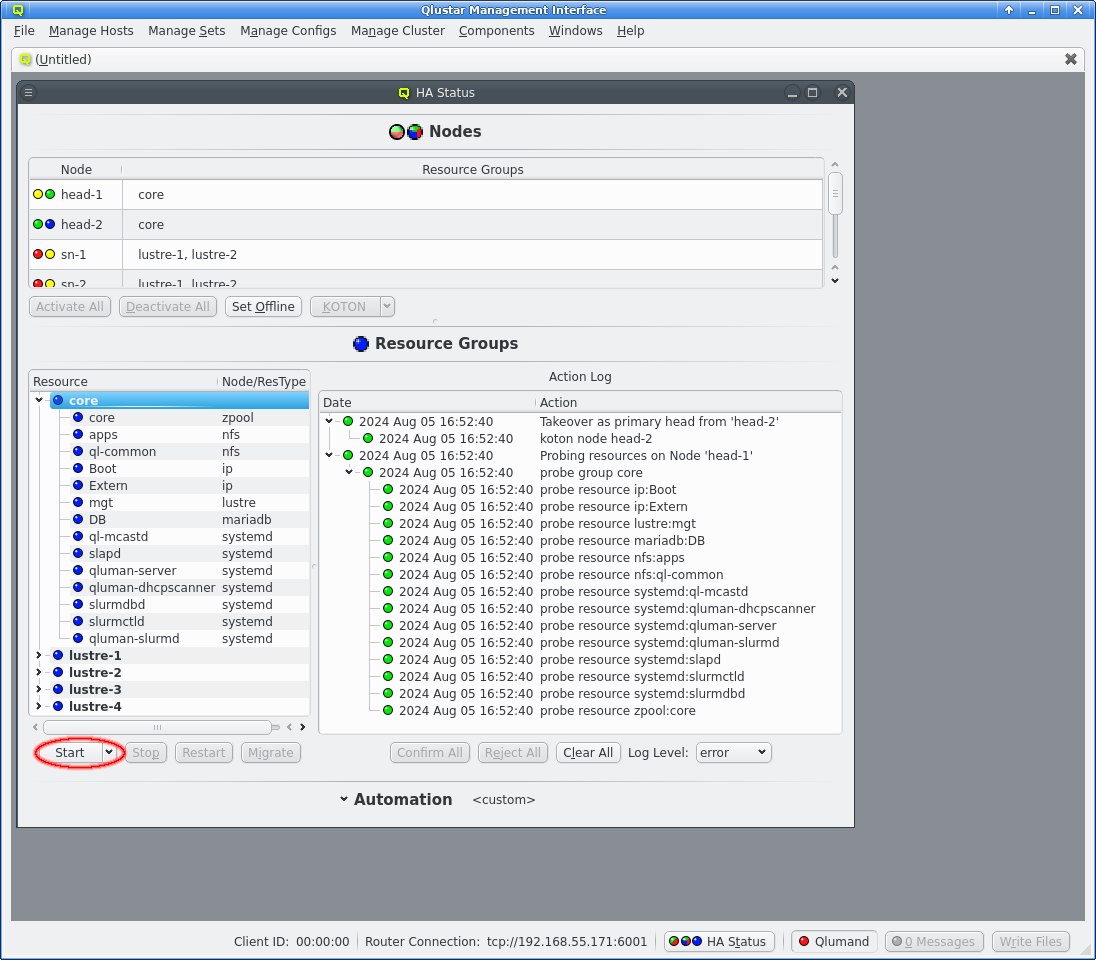
Once the other head-node is marked offline the core Resource Group can be started like normal and the cluster will run in a degraded mode. QHAS will still try to restart resource on failure but it won’t be able to recover from an error that isn’t resolved with a simple resource restart. Without a second head-node it can’t migrate resources. This does not affect other pairs of nodes though. Each Resource Group is independent. As long as both hosts for a Resource Group are online migration and koton can happen.
|
The same applies to Resource Groups on other nodes. Both nodes need to be in a known state for resources to be started. Unlike head-nodes other nodes can be set offline from qluman-qt. |